코딩 교육 TIL
2024-02-06 AI 코딩 TIL
HyunjunPark
2024. 2. 16. 20:40
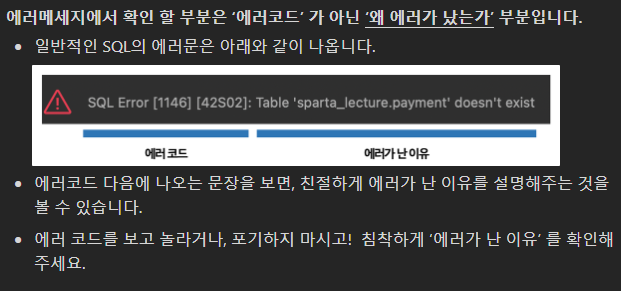
SQL을 사용하기 위해서는 디비버라는 어플리케이션 사용이 유용하다.
데이터를 나누는 방법으로 테이블이라는 커다란 칸 안에 칼럼으로 분류를 해주고 있다.
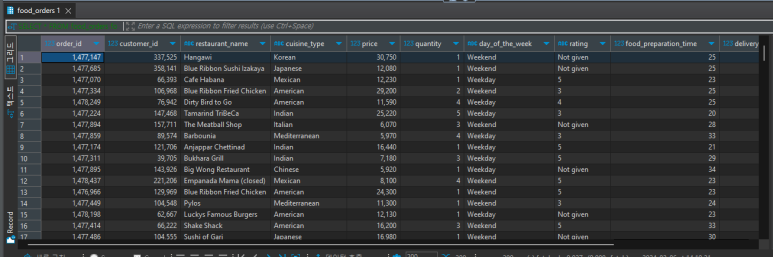
SELECT * FROM food_orders fo
테이블 안에 전체 칼럼 가져오기
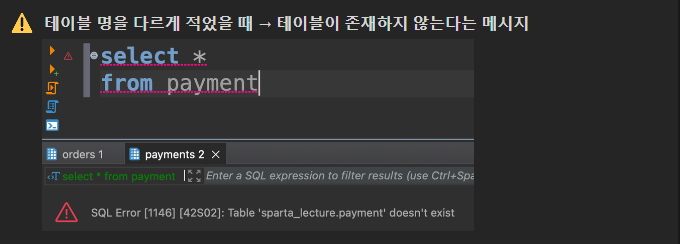
현제 연결 되어 있는 서버의 데이터에는 아래와 같은 테이블이 있다.
SELECT restaurant_name, addr FROM food_orders fo
별명 지정 방법 : 컬럼 옆쪽에 별명을 적어줍니다. (아래 두 가지 방법 모두 가능합니다)
- 방법1 : 컬럼1 as 별명1 - 방법2 : 컬럼2 별명2
|
구분
|
영문, 언더바
|
특수문자, 한글
|
|
방법
|
별명만 적음
|
“별명” 으로, 큰 따옴표 안에 적어줌
|
|
예시
|
ord_no
|
“ord no” ”주문번호”
|
select order_id as ord_no, restaurant_name "식당 이름" from food_orders
SELECT order_id ord_no, price "가격", quantity '수량' FROM food_orders fo
● 조건에 맞는 데이터만 필요할 때, SQL로 필터링하기 ( WHERE )
가져온 칼럼 중에서 필요한 데이터만 필터링하고 싶을 때 사용 할 수 있다.
예시로 손님의 나이 중에 21살인 사람만 목록을 가져오고 싶다면?
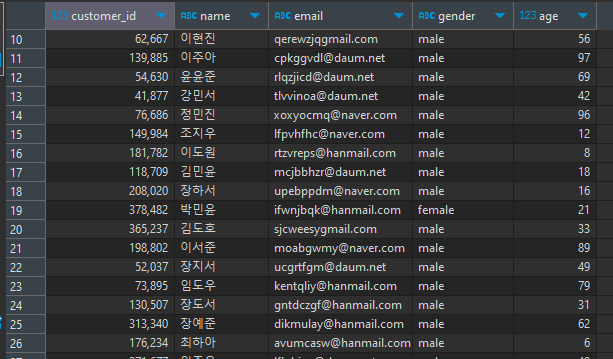
SELECT * FROM customers c WHERE age=21
SELECT * FROM customers c WHERE gender = 'male'
select * from 테이블 where 필터링 조건 (eg. 20살 이상)
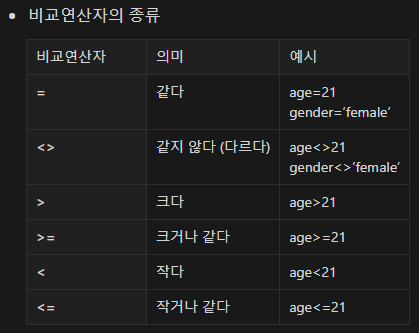
● WHERE + (비교연산, BETWEEN, IN, LIKE)
WHERE을 포함한 비교문을 사용할 때 나타내는 연산표시
● BETWEEN : 일정 범위에 필요한 값을 가져오기
SELECT * FROM customers c WHERE age BETWEEN 10 AND 20
● IN : 칼럼의 값 중에서 내가 원하는 값만 가져오기
SELECT * FROM customers c WHERE age IN (21,25,27)
SELECT * FROM customers c WHERE c.name IN ('윤주아','정현준')
● LIKE : 완전히 같은 값은 아니지만 비슷한 값을 가져오기 위해
SELECT * FROM customers c WHERE c.name LIKE '김%'
김으로 시작하는 모든 글자를 가져올 수 있다.
SELECT * FROM customers c WHERE age >= 21 AND gender = 'male'
조건을 합치기 위해서는 'AND'를 사용하여 조건문을 합쳐준다.
SELECT * FROM customers c WHERE age = 21 OR gender = 'male'
나이가 21살이거나 성별이 남자인 사람들 전부
SELECT * FROM customers c WHERE NOT gender = 'male'
SELECT * FROM food_orders fo WHERE cuisine_type = 'korean' AND price >= 30000
한국음식점이며 가격이 30000원 이상인 가게
WHERE cuisine_type = 'korean'로 입력
SELECT restaurant_name '음식점 이름', order_id '고객번호', food_preparation_time '준비시간', cuisine_type '음식점 타입' FROM food_orders fo WHERE food_preparation_time BETWEEN 20 AND 30 AND cuisine_type = 'Korean'
데이터 조회와 엑셀 함수 적용을 한 번에 끝내기
(SUM, AVG, COUNT, MIN, MAX)
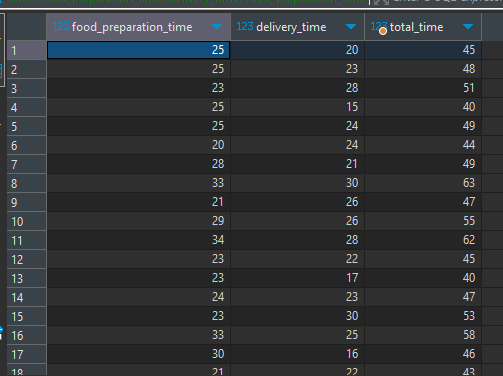
select food_preparation_time, delivery_time, food_preparation_time + delivery_time as total_time from food_orders
as 말고 한 칸 띄우고 ""로 사용해도 된다.
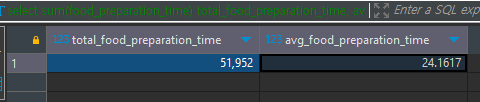
select sum(food_preparation_time) total_food_preparation_time, avg(delivery_time) avg_food_preparation_time from food_orders
칼럼의 전체 값을 합산 및 평균을 계산하여 준다.
SELECT COUNT(1) count_of_orders, COUNT(DISTINCT customer_id) count_of_customers FROM food_orders
첫 번째 COUNT는 모든 값을 카운팅 한 것이며
두 번째 카운트는 중복값을 제외하고 카운트를 한 것이다.
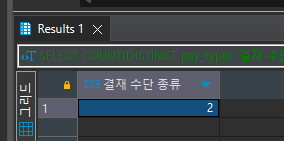
SELECT COUNT(DISTINCT pay_type) '결재 수단 종류' FROM payments p
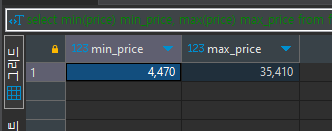
select min(price) min_price, max(price) max_price from food_orders
select MIN(quantity) "갯수 최소값", MAX(quantity) "갯수 최댓값" from food_orders
WHERE 절로 원하는 데이터를 뽑고, 계산해 보기
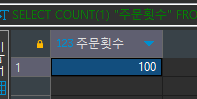
SELECT COUNT(1) "주문횟수" FROM food_orders WHERE price >= 30000
30000원 이상 주문한 개수는
100개이다.
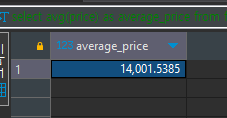
select avg(price) as average_price from food_orders where cuisine_type='Korean'
범주별 연산을 한 번에 끝내기 (GROUP BY)
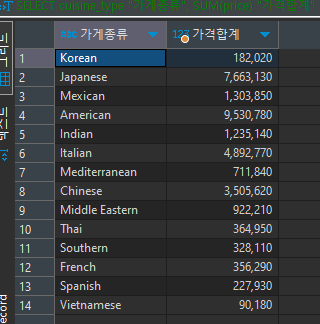
SELECT cuisine_type "가게종류", SUM(price) "가격합계" FROM food_orders GROUP BY cuisine_type
SELECT cuisine_type "가게종류", price "주문금액", COUNT(1) "주문횟수" FROM food_orders WHERE price >= 30000 GROUP BY cuisine_type
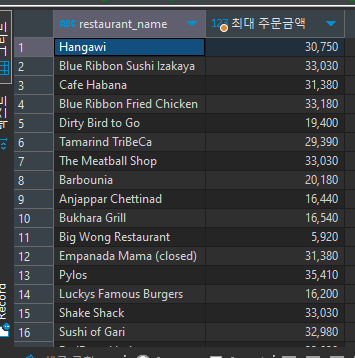
select restaurant_name, max(price) "최대 주문금액" from food_orders group by restaurant_name
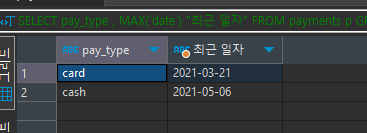
SELECT pay_type , MAX(`date`) "최근 일자" FROM payments p GROUP BY pay_type
date 값을 가져오는데 ''을 붙여서 가져올 수도 있다.
Query 결과를 정렬하여 업무에 바로 사용하기 (ORDER BY)
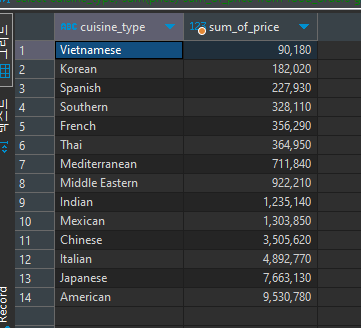
select cuisine_type, sum(price) sum_of_price from food_orders group by cuisine_type order by sum(price)
sum(price)의 값이 작은 값부터 큰 값 순으로 오름차 순으로 정렬
select cuisine_type, sum(price) sum_of_price from food_orders group by cuisine_type order by sum(price) DESC
DESC를 끝에 붙이면 반대로 내림차순으로 정렬이 된다.
select restaurant_name "음식점이름", MAX(price) "최고가격" from food_orders group by restaurant_name order by MAX(price)
음식점 별로 가장 큰 금액 조회 후 내림차 순으로 정렬
SELECT * FROM customers c GROUP BY name ORDER BY name
SELECT * FROM customers c GROUP BY name ORDER BY gender, name
콤마를 찍어서 두 가지로 정렬해 줄 수 있으며 왼쪽순으로 먼저 정렬을 해준다.
SELECT cuisine_type "음식점이름", MIN(price) "최솟값", MAX(price) "최댓값" FROM food_orders fo GROUP BY 1 ORDER BY 2 DESC
음식점이름과 최소가격 최대가격을 구하고 최소 가격 내림차 순으로 정렬
업무 필요한 문자 포맷이 다를 때, SQL로 가공하기 (REPLACE, SUBSTRING, CONCAT)
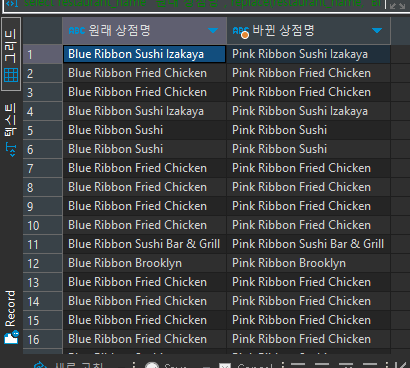
lect restaurant_name "원래 상점명", replace(restaurant_name, 'Blue', 'Pink') "바뀐 상점명" from food_orders where restaurant_name like '%Blue Ribbon%'
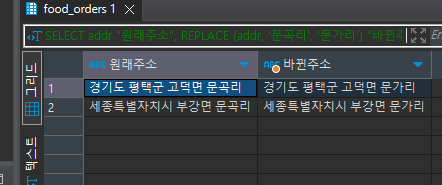
SELECT addr "원래주소", REPLACE (addr, '문곡리', '문가리') "바뀐주소" FROM food_orders fo WHERE addr like '%문곡리%'
문곡리라는 글자를 찾아서 문 가리로 변경을 해주는 것
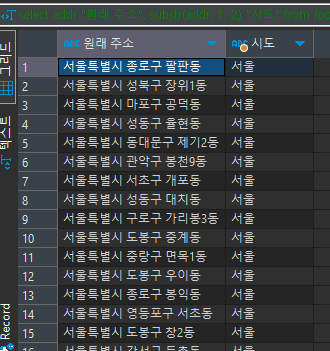
elect addr "원래 주소", substr(addr, 1, 2) "시도" from food_orders where addr like '%서울특별시%'
서울특별시 % 의 주소 내용들 중에 앞에서
두 번째 글자까지만 입력할 수 있도록
select restaurant_name "원래 이름", addr "원래 주소", concat('[', substring(addr, 1, 2), '] ', restaurant_name) "바뀐 이름" from food_orders where addr like '%서울%'
글자내용을 넣고 싶은 대로 합치거나 더할 수 있다.
문자 데이터를 바꾸고, GROUP BY 사용하기
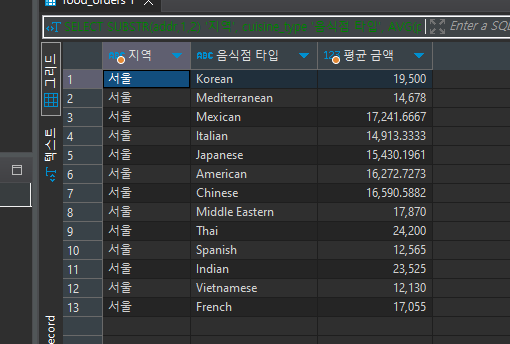
SELECT SUBSTR(addr,1,2) '지역', cuisine_type '음식점 타입', AVG(price) '평균 금액' FROM food_orders fo WHERE addr LIKE '서울%' GROUP BY 2
서울 지역만 필터링해서 각음식점 별로 나눈 다음 평균금액을 설정한다.
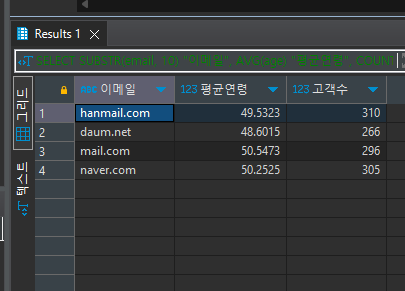
SELECT SUBSTR(email, 10) "이메일", AVG(age) "평균연령", COUNT(1) "고객수" FROM customers c GROUP BY 1
고객의 평균 연령을 구하고 이메일 도매인에 해당하는 고객수를 카운팅 한다
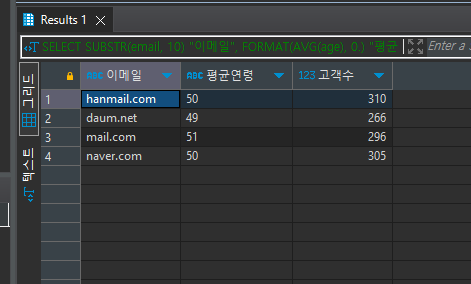
FORMAT(AVG(age), 0.) "평균연령"
FORMAT : 내가 원하는 숫자만 표시 가능하다.
예시) ##0.0000 : 소수점 4째 자리까지.
# = 숫자가 있으면 표기
0 = 숫자가 있던 없던 표기
SELECT SUBSTR(email, 10) "이메일", FORMAT(AVG(age), 0.) "평균연령", COUNT(1) "고객수" FROM customers c GROUP BY 1
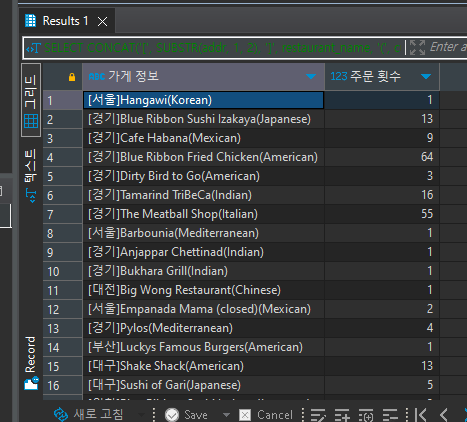
SELECT CONCAT('[', SUBSTR(addr, 1, 2), ']', restaurant_name, '(', cuisine_type, ')') "가게 정보", COUNT(1) "주문 횟수" FROM food_orders fo GROUP BY 1
가게 정보를 concat 합쳐서 맞추고 count로 동일한 값을 카운트