
-
CPU와 메모리
-
푸드 트럭
-
컴퓨터
-
입력장치
-
출력장치
-
cpu의 구성
-
메모리
-
CPU , I/O Burst Cycle
-
선점 스케쥴링(Preemptive Scheduling)
-
선점 1.Priority Scheduling(우선순위 스케쥴링)
-
선점 2.Round Robin(라운드로빈)
-
선점 3.Multilevel-Queue(다단계 큐)
-
비선점 스케쥴링(Non-Preemptive Scheduling)
-
비선점 1. FCFS (First Come , First Serve)
-
비선점 2. SJF(Shorted Job First)
-
비선점 3. HRN (Highest Response-ratio Next)
-
지역성??
-
시간 지역성
-
공간 지역성
-
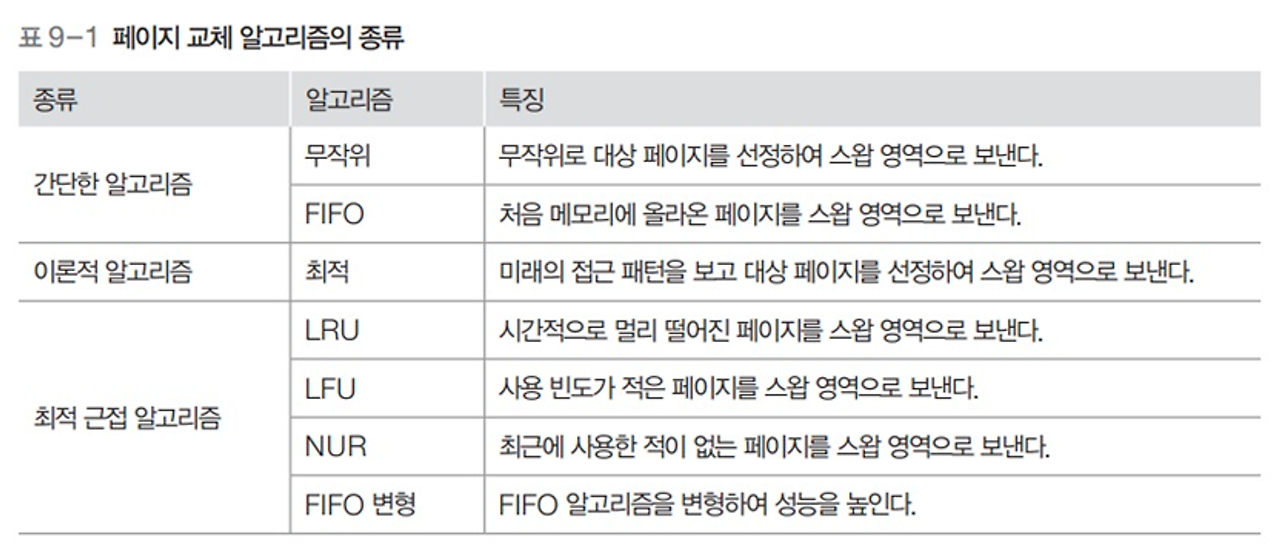
페이지 교체 알고리즘
-
프로세스 생명주기
-
대기 큐 (Waiting Queue)
-
**주-보조 교환 (Swapping)**
-
문맥 교환 (Context Switching)
-
커널 프로세스의 메모리
-
쓰레드 풀
-
쓰레드 풀을 사용하는 이유
-
쓰레드 풀의 장단점
-
DBMS 발전 과정
-
문서형(Document) 데이터베이스
-
Key-Value 타입
-
Wide-Column Store 데이터베이스
-
그래프(Graph) 데이터베이스
이번주부터는 cs에 대해서 공부를 시작합니다!
CPU와 메모리
우리가 사용하는 컴퓨터의 구조를 일상생활에 비교를 해보자!
푸드 트럭

컴퓨터


컴퓨터에는 입력장치 출력장치 기억장치 연산장치 등등이 있습니다.
입력장치
마우스 키보드 카메라
출력장치
스피커 모니터 등등
cpu의 구성


사람의 두뇌에 해당되는 cpu의 구성이다.
cpu안에서도 산술 논리를 위한 (ALU), 제어(CU)를 위한 버스, 메모리 유닛으로 레지스터와 캐시가 있습니다.
프로세서에 위치한 고속 메모리로 극히 소량의 데이터나 처리 중인 중간 결과와도 같은 프로세서가 바로 사용할 수 있는 데이터를 담고 있는 영역을 레지스터라고 한다. 컴퓨터 구조에 따라 크기와 종류가 다양하다. 용도에 따라 범용 레지스터와 특수목적 레지스터로 구분된다
범용 레지스터 : 연산에 필요한 데이터나 연산 결과를 임시로 저장한다. 특수목적 레지스터 : 특별한 용도로 사용하는 레지스터이다
✅ 특수목적 레지스터는 아래와 같은 다양한 레지스터가 존재합니다.
- 메모리 주소 레지스터: (MAR) : 읽고 쓰기 위한 주기억장치의 주소를 저장한다.
- 프로그램 카운터 (PC) : 다음에 수행할 명령어의 주소를 저장
- 명령어 레지스터 (IR) : 현재 실행 중인 명령어를 저장
- 메모리 버퍼 레지스터 (MBR) : 주기억장치에서 읽어온 데이터나 저장할 테이터를 임시로 저장
- 누산기 (AC, ACCUMULATOR) : 연산 결과를 임시로 저장
컴퓨터의 성능에서 가장 중요한 부분인 CPU의 성능은 클럭과 코어로 표현할 수 있다.
메모리

- 레지스터 = CPU
- 캐시메모리(SRAM), 메인 메모리(DRAM) = 주 기억장치
- 하드디스크(HDD) = 보조 기억장치
레지스터는 연산을 위한 데이터 공간
캐시는 잠깐두는 곳
주기억장치(RAM)는? DRAM과 SRAM이 있는데
SRAM은 캐시와 레지스트리를 의미하고
우리가 일반적으로 알고 있는 램은 DRAM에 속한다.
간단하게 느낌을 보자면 하드와 CPU 간에 속도 차이를 위해서 있는 것이 DRAM이고 그 DRAM과 CPU 간의 속도차이를 위해서 있는 것이 SRAM인 것 같습니다.
CPU와 메모리의 구조는 하버드 구조와 폰노이만 구조가 있습니다!
즉 데이터를 얼마나 빠르게 전달하는지가 성능에 중요하다고 할 수 있습니다!
CPU심화
프로세스와 스레드
카카오톡을 실행시키는 프로세스
메시지를 발송처리하는 스레드
오버헤드 : 프로세스가 필요한 자원보다 더 많이 사치를 부리는 것
사용률 : 프로세스가 최대한 자원을 많이 받고 빨리 처리하는 것
기아 현상 : 프로세스가 자원할당을 못 받아서 배고픈 상태
CPU , I/O Burst Cycle

- 프로세스 실행은 “CPU실행 ↔ 입/출력 대기” 의 반복을 의미합니다.
- CPU Burst
- 프로세스의 사용 중에 연속적으로 CPU를 사용하는 구간을 의미합니다.
- 즉, 실제 CPU를 사용하는 스케쥴링의 단위이다.
- I/O Burst
- 프로세스의 실행 중에 I/O작업이 끝날 때까지 Block 되는 구간을 의미합니다.
스케쥴링은 OS가 CPU를 사용권을 선점하나 아니냐에 따라 선점/비선점으로 나뉜다.
선점 스케쥴링(Preemptive Scheduling)
선점 1.Priority Scheduling(우선순위 스케쥴링)

우선순위가 빠른 순으로 진행이 된다.
하지만 우선순위가 낮은 프로세스의 경우 무한 대기를 할 수 있다.
선점 2.Round Robin(라운드로빈)
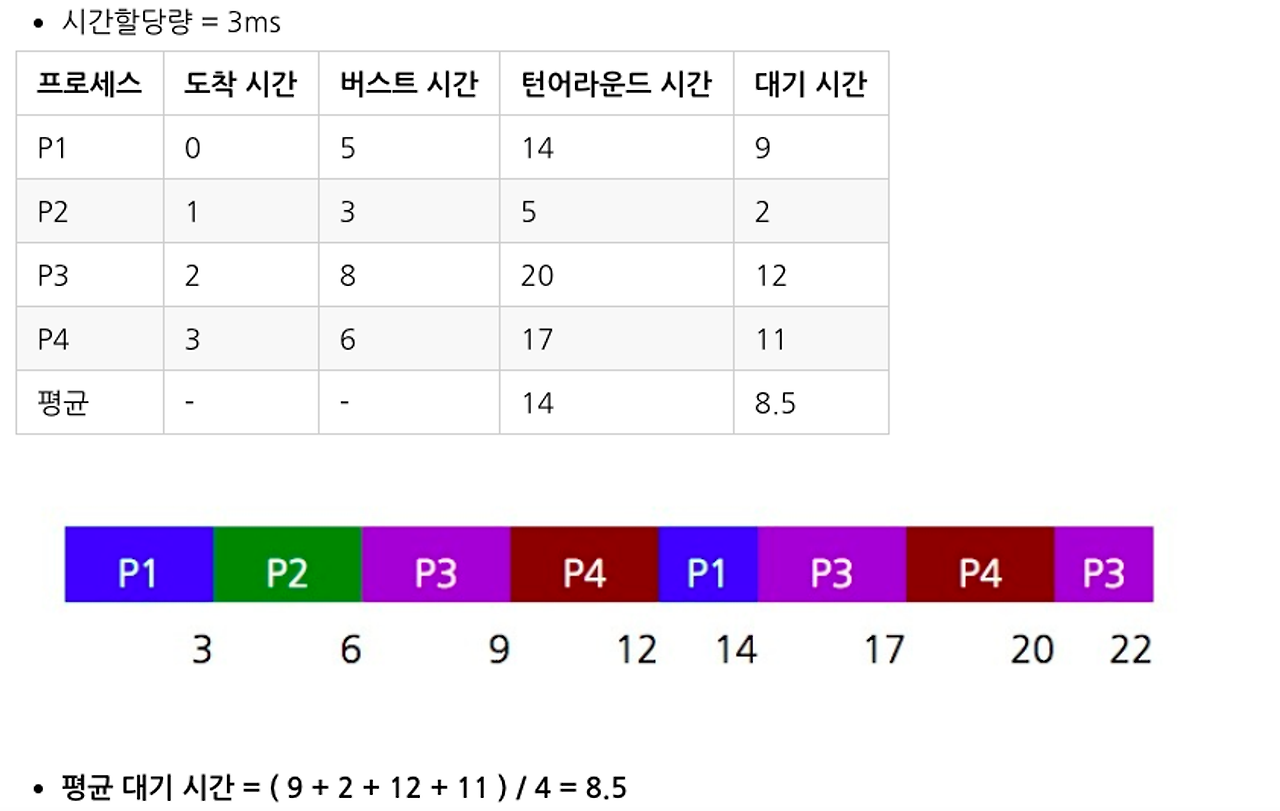
각 프로세스를 실행할 때에 시간마다 나누어서 실행을 한다.
우선순위가 낮을 경우 사용을 하면 골고루 배치가 가능하나
프로세스 간의 전환(=문맥전환)이 자주 일어나서 시간낭비가 있다.
선점 3.Multilevel-Queue(다단계 큐)
준비완료 큐를 여러 개의 큐로 분류하여 각 큐가 각각 다른 스케쥴링 알고리즘을 가지는 방식. 메모리 크기, 우선순위, 유형 등 프로세스의 특성에 따라 하나의 큐에 영구적으로 할당된다. 따라서 큐와 큐 사이에도 스케쥴링이 필요하다. 우선순위 방식 혹은 시분할 방식으로 한다.
우선순위 방식
고정 우선순위의 선점형 방식으로 구현되며, 따라서 우선순위에 따른 큐의 스케쥴링은 절대적이다. 예를 들어,
우선순위가 높은 Forground Queue
- 대화형 프로세스를 위한 큐
- Round Robin
우선순위가 낮은 Background Queue
- 연산작업을 처리하는 프로세스 큐
- FCFS
여기서 Forground큐가 비어있지 않는 한 Background큐는 먼저 실행될 수 없으며, Background큐가 먼저 실행 중이더라도 Forground큐에 프로세스가 들어오면 선점된다.
비선점 스케쥴링(Non-Preemptive Scheduling)
처리시간 예측에 용이합니다.
긴 처리시간의 프로세스를 만나면 다른 프로세스를 대기시킬 수 있으므로 처리율이 떨어질 수 있다는 단점이 있습니다.
비선점 1. FCFS (First Come , First Serve)

계산대처럼 앞에 많은 시간을 기다려야 하면 짧은 처리프로세스를 가지고 있어도 앞에 프로세스가 끝날 때까지 대기를 해야 한다는 단점이 존재
다른 방식에도 FCFS라는 단어가 많이 보이는데 간단하게 먼저 들어온 프로세스가 먼저 처리가 된다는 의미이며 기본적인 구조 방식으로 특정 조건이 성립되지 않는 한 이 규칙을 기본으로 잡고 실행을 합니다.
비선점 2. SJF(Shorted Job First)

수행시간이 짧다고 판단이 되는 프로세스부터 먼저 수행을 한다.
가장 적은 평균대기시간을 처리
비선점 3. HRN (Highest Response-ratio Next)
💡 HRN 특징
- 우선순위를 계산하여 점유 불평등 보완(SJF 단점 보완)
- 우선순위 = (대기시간 + 실행시간) / (실행시간)
지역성??
지속적인 반복작업을 진행할 때 빠르게 값을 가져올 수 있도록 하는 것
지역성에는 시간지역성과 공간지역성이 있습니다
시간 지역성
최근 사용한 데이터에 다시 접근하려는 특성
ex) for문 안에 선언된 i는 반복문 안에서 계속해서 접근이 이루어지는 변수이다. 최근에 사용했기 때문에 계속 접근해서 +1 이 이루어지는 것이다. (i 변수에 대한 시간 지역성)
for(let i=0; i<5; i++){
console.log(i) // 0 1 2 3 4
}공간 지역성
최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성
ex) 배열 arr이라는 공간에 i가 연속적으로 할당되어 접근하는 방식 (arr 배열 원소에 대한 공간 지역성)
let arr = [];
for(let i=0; i<5; i++){
arr.push(i)
}
// arr = [0,1,2,3,4]
페이지 교체 알고리즘
프로세스와 스레드
내 컴퓨터의 작업관리자를 보면 사용 중인 프로세스를 볼 수 있습니다

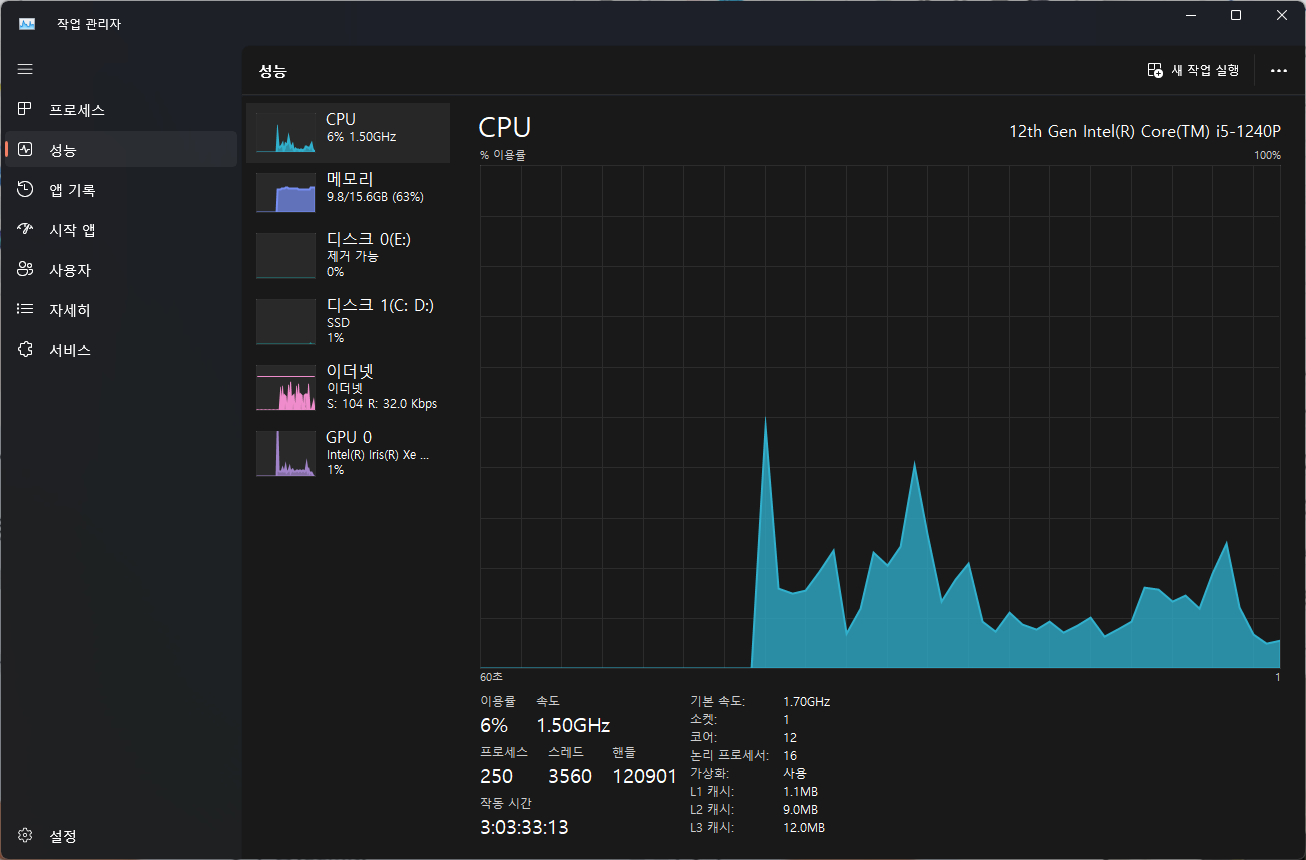
CPU의 상태를 보면 프로세스의 수와 스레드의 사용량을 볼 수 있습니다.
프로세스 생명주기
📌 프로세스 상태변화 = 프로세스 생명주기
프로세스 생명주기와 프로세스 상태변화는 같은 의미입니다.
- 🟠은 프로세스들의 상태를 의미하고
- 🔜 은 스케쥴링에 따라 상태가 변화되는 동작을 의미합니다.
- 상태변화 = 생명주기
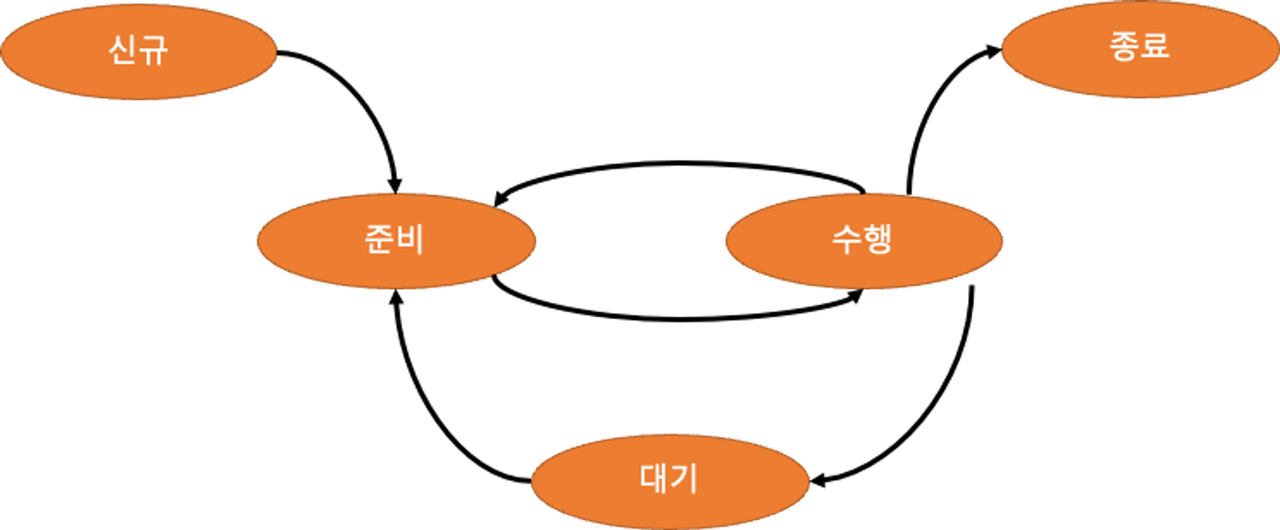
신규 - 준비 - 수행 - 대기 OR 종료
📌 수행상태에서 해제되는 경우 예시
- 수행 -> 준비(중단)
- CPU의 과부하가 판단되는 경우
- 수행 -> 대기
- I/O 나 event wait가 있을 경우
- 이 후 I/O나 evet가 끝나면 ready 상태로 복구
대기 큐 (Waiting Queue)

잡 큐 : 하드 -> 메모리로 갈 때 메모리가 가득 차면 잠시 하드에서 대기를 하는 공간
레디 큐 : 메모리 -> CPU 갈 때 대기 하는 큐
디바이스 큐 : CPU -> 입출력 장치 위와 동일하게 대기하는 큐 (프린터, 마우스... 등등)
큐 스케쥴링
**Job Scheduler :**
- Job Queue의 프로그램들을 어떤 순서로 메모리에 올릴 것인지 결정합니다.
- 이러한 과정은 프로그램이 새로 시작될 때, 메인메모리가 가득 찬 경우 등의 상황에만 발생하므로 자주 일어나지 않고 어쩌다 한번(수분 ~ 수십 분) 일어납니다.
📌 Long Term Scheduler
프로그램이 새로 시작될 때, 메인메모리가 가득찬 경우 등의 상황에만 발생하므로 자주 일어나지 않고 어쩌다 한번(수분 ~ 수십분) 일어나며, 이처럼 긴 간격으로 동작하는 스케줄러를 Long Term Scheduler라고 합니다
**CPU Scheduler :**
- Ready Queue의 프로세스들을 어떤 순서로 서비스할 것인지에 대한 스케줄러입니다.
- 모든 스케줄링 중에서 CPU 스케줄링이 가장 중요합니다.
📌 Short Term Scheduler
- 시공유 시스템의 경우 이러한 과정은 1초에도 수십번에서 많게는 수백번도 일어나기 때문에 이러한 스케줄러를 Short Term Scheduler라고 합니다.
**Device Scheduler :**
- Device Queue의 프로세스들을 어떤 순서로 I/O 장치를 이용하게 할 것인지에 대한 스케줄러입니다.
- 이는 Disk Scheduler, Printer Scheduler, Mouse Scheduler 등 I/O, 보조기억 장치 스케줄러를 통틀어 가리키는 말입니다.
📌 I/O Bound Process VS CPU Bound Process
- I/O Bound Process
- 대부분의 시간을 I/O하는데 쓰는 프로세스들을 의미합니다.
- CPU Bound Process
- 대부분의 시간을 CPU로 연산하는데 쓰는 프로세스를 의미합니다.
✅ 운영체제(Job Scheduler)는 이들을 적절하게 배합하여 I/O 장치와 CPU 모두 너무 오랫동안 쉬게 하지 않아야 합니다. (성능을 위해)
**주-보조 교환 (Swapping)**
**1) Swapping :**
- 서버와 같이 여러 사용자가 하나의 메모리를 공유하는 경우에 만약 한 사용자가 자리를 비우면 그 사용자가 돌아올 때까지 해당 프로세스에 메모리를 할당할 이유가 없습니다! 😱
- 때문에 PCB(Process Control Block)의 CPU Time 등을 확인해서 오랫동안 동작이 없는 프로세스는 잠시 HDD로 내려놓고, 다른 프로세스를 실행하거나 기존 프로세스에 메모리를 더 할당하는 등 메모리를 더 효율적으로 활용합니다.
- 그러다가 동작 없던 프로세스 사용자가 돌아와서 작업을 수행하면 다시 HDD에서 메모리로 프로세스를 올립니다.
- **Swap Out**
- 메모리에서 HDD로 내리는 작업
- **Swap In**
- HDD에서 다시 메모리로 올리는 작업
- 이렇게 임시 메모리의 목적으로 사용되는 HDD 공간을 Backing Store 혹은 Swap Device라고 합니다.
📌 medium Term Scheduler
- Swapping 역시 여러 프로세스들이 HDD로 내려가고 다시 메모리로 올라오고 하기 때문에 어떤 순서로 프로세스를 먼저 내리고 올릴지 결정해야합니다.
- 이러한 스케줄링 작업은 Short Term Scheduling 보다는 적게 일어나지만 Long Term Scheduling 보다는 자주 일어납니다.
- 때문에 이러한 스케줄링 작업(Swapping Scheduling)을 Midium Term Scheduling이라고 합니다.
오... 컴퓨터를 쓰면 메모리 확장을 위해서 스왑기능을 활성화하는 경우를 자주 보았는데 원리가 이런 원리였는지는 오늘 알았습니다.
그냥 하드디스크의 일부를 메모리처럼 쓰는 줄 알았는데 메모리에서 넘치는 부분은 잠시 보관하는 용도였을 줄이야..
문맥 교환 (Context Switching)
CPU가 프로세스를 처리할 때 시간마다 돌아가면서 동작을 하는데 속도가 엄청 빠르기 때문에 우리가 보기에는 동시에 작업이 진행이 되는 것처럼 보입니다.
프로세스 메모리


위아래 동일한 그림
1) Code 영역
- 실행할 프로그램의 코드가 저장됩니다. CPU는 이 영역에서 명령어를 하나씩 가져와 처리하게 됩니다.
2) Data 영역
- 전역변수와 정적변수가 저장됩니다.
- 이 변수들은 프로그램이 시작될 때 할당되어 프로그램 종료 시 소멸됩니다.
- BSS(Block Stated Symbol) 영역?
- BSS 영역에는 초기화 되지 않은 전역변수가 저장됩니다.
- 초기화 된 전역변수는 Data 영역에 저장되어 비휘발성 메모리인 ROM에 저장되는데 이 부분은 비용이 많이 들어 RAM에 저장될 것과 ROM에 저장될 것을 구분하기 위해 영역을 구분해 사용합니다.
3) Stack 영역
- 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터(지역변수, 매개변수, 리턴값 등)를 임시로 저장하는 공간
- 이 영역은 함수 호출시 기록하고 함수의 수행이 완료되면 사라진다. 메커니즘은 자료구조(stack)에서 배운 LIFO(Last In First Out) 방법으로 저장/출력 합니다.
- 컴파일 시 stack 영역의 크기가 결정되기 때문에 무한정 할당 할 수 없습니다.
- 따라서 재귀함수가 반복해서 호출되거나 함수가 지역변수를 메모리를 초과할 정도로 너무 많이 가지고 있다면 stack overflow가 발생합니다. (알고리즘 시험풀때 많이 발생!)
위 세 영역은 컴파일할 때 data, stack 영역의 크기를 계산해 메모리 영역을 결정합니다!
4) Heap 영역
- 동적 데이터 영역입니다.
- 메모리 주소 값에 의해서만 참조되고 사용되는 영역입니다. 따라서, 프로그램 동작 시(런타임)에 크기가 결정됩니다.
- 예를 들어, stack에서 pointer 변수를 할당하면 pointer가 가리키는 heap 영역의 임의의 공간부터 원하는 크기만큼 할당해 사용하게 됩니다.
- heap 영역은 런타임에 결정된다. 자바에서는 객체가 heap영역에 생성되고 GC에 의해 정리됩니다.
- GC 는 Garbage Collector 의 약자로, 안쓰는 heap 영역을 치우는 쓰레기 청소부👷♀️입니다.
커널 프로세스의 메모리
커널은 명령을 즉시 실행할 수 있는 인터프리터 역할을 한다.
컴퓨터 상에서 프로그램 강제 종료 같은 걸 할 수 있는 역할

커널은 CODE, DATA, STACK이 있고 HEAP은 없습니다.
✅ 정리하기
1) 프로세스 : 메모리에 올라온 프로그램
2) 프로세스 생명주기 : 신규 - 준비 - 수행 - 대기 - 종료
3) PCB : 프로세스의 실행 정보와 상태 정보를 저장하는 자료구조 (PID, PC, Register, MMU 등)
4) 대기 큐 (Queue) : Job, Ready, Device Queue 등
5) Scheduler : Job, CPU, Device Schduler 등
6) Swapping : 안 쓰는 프로세스 HDD로 내리고, 다시 쓰이면 메모리로 올리는 작업
7) Context Switching : Running 프로세스를 Ready로 만들고 다른 프로세스로 전환
8) Dispatcher : 콘텍스트 스위칭할 때 필요한 정보(PCB를 저장하고 꺼내는 프로그램)
9) CPU 시간공유 시스템 : (대부분의) OS에서 프로세스(스레드)가 시간단위로 나누어서 CPU를 사용할 수 있도록 관리해 주는 시스템
10) 프로세스 메모리 공간 : 프로세스 주소 공간은 Code, Data, Stack, Heap으로 구성됨
11) 커널 : 커널은 대부분의 운영 체제(OS)의 주요 구성 요소이며 컴퓨터 하드웨어와 프로세스를 잇는 핵심 인터페이스
12) PCB : 프로세스의 실행 정보와 상태 정보를 저장하는 자료구조로 커널 프로세스에 존재
스레드
스레드와 프로세스의 차이점
프로세스 안에 스레드가 있지만 하는 역할이 조금 다릅니다.
스레드는 프로세스 내에서 실행되는 실행 단위이며, 쓰레드 풀은 쓰레드를 미리 생성해 두어 작업 처리에 사용되는 쓰레드를 제한된 개수만큼 정해 놓고 작업 큐에 들어오는 작업들을 하나씩 쓰레드가 맡아 처리하는 기법입니다.
프로그램을 실행하는 주체 = 프로세스
(예시 = 치킨집)
작업을 처리하는 주체 = 쓰레드
(예시 = 치킨집 직원)
치킨집 안에 공간과 재료를 같이 쓴다 = 자원 공유
모든 프로세스 안에는 스레드가 한 개이상이 있어야 한다.
프로세스의 구성으로는 CODE, DATA, HEAP, STACK이 있으며 이 것을 공유한다.
만약에 프로세스로만 작업을 한다면???
1. 프로세스만으로 작업하면 시간이 많이 소요가 됩니다.
2. 프로세스 사이에 통신이 어렵습니다.
3. 생성에 오버헤드 많음
쓰레드 프로세스로부터 공유를 받으면 개별적으로 STACK만을 가지고 있습니다.
이로 인하여 작은 단위에 실행이 구현이 되며
생성 및 소멸의 오버헤드가 감소
스레드 간 자원 공유로 빠른 스위칭 가능
프로세스들의 통신 어려움 해소

프로세스는 다음의 특징을 갖습니다.
- 각각 독립된 메모리 영역(Code, Data, Stack, Heap)을 할당받습니다.
- 코드 영역(code area): 프로그래머가 작성한 프로그램이 저장되는 영역
- 데이터 영역(data area): 코드가 실행되면서 사용한 환경이나 파일들의 각종 데이터들이 모여있습니다.
- 스택 영역(stack area): 호출한 함수가 종료되면 되돌아올 메모리의 주소나 지역 변수 등이 저장됩니다.
- 힙 영역(heap area): 동적으로 할당되는 데이터를 위해 존재합니다.
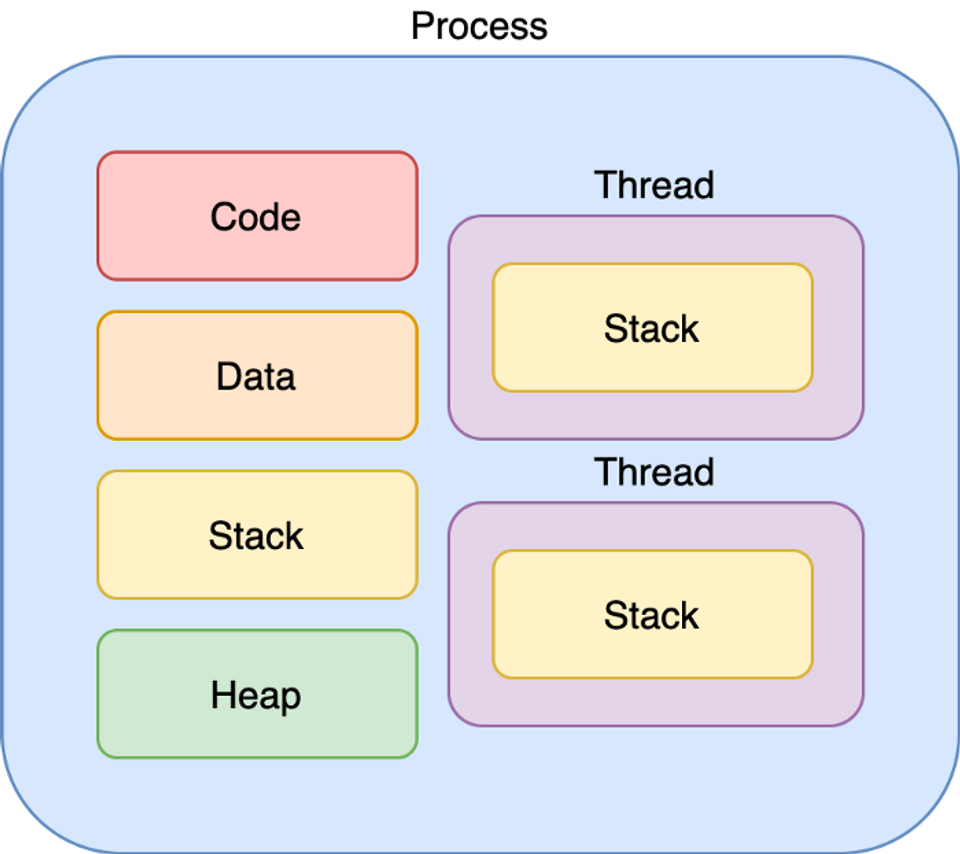
📌 치킨집에서 각자 일하는 공간(Stack)이 있지만,
- 업무 메뉴얼(Code)도 같이 보고
- 손님의 주문(Data)도 같이 받고
- 손님이 주문한 치킨을 서빙 하는 홀 공간(Heap)도 같이 쓴다는 점과 비슷합니다.
👌 **멀티 프로세스 대신 멀티 스레드를 사용하는 이유**
**`자원 효율성 증대`, `처리 비용 감소`, `응답 시간 단축`**
쓰레드 풀
- 컴퓨터 프로그래밍에서 쓰레드 풀은 컴퓨터 프로그램에서 실행의 동시성을 달성하기 위한 소프트웨어 디자인 패턴입니다.
- 프로그램이 작업을 동시에 실행할 수 있도록 여러 스레드를 미리 생성해 두고 유지 관리합니다.
- 여러 Thread를 동시에 만들어 실행(병렬처리)할 수 있습니다.
- 🤫 그렇다고 해서 Thread를 계속 늘려가는 건 좋은 것일까? 당연히 아닙니다.
하드웨어의 제한적인 사항(CPU, Memory 등)이 있기 때문에 관리할 필요가 있습니다.
그래서 스레드 풀 이라는 개념을 이용합니다.
- 쓰레드 풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해 놓고 작업 큐(Queue)에 들어오는 작업들을 하나씩 스레드가 맡아 처리하는 것을 말합니다.
- 치킨집에서 직원 뽑기가 어려우니 직원들을 미리 뽑아두는 것과 비슷합니다.
해야 할 일을 순서대로(작업 큐) 직원들에게 할당해주며 처리하도록 합니다.
💁 **스레드 풀의 동작**
1. 초기화: 쓰레드 풀을 사용하기 전에 초기화해야 합니다. 이 단계에서는 쓰레드 풀의 크기, 최대 쓰레드 수, 작업 큐 등의 매개변수를 설정합니다.
2. 작업 수신: 쓰레드 풀은 작업을 수신하고 처리할 준비를 합니다. 작업은 일반적으로 작업 큐에 추가됩니다.
3. 작업 수행: 스레드 풀에서는 미리 생성된 쓰레드들이 작업 큐를 모니터링하고 대기 중인 작업을 가져와 처리합니다. 이때 쓰레드 풀 내의 쓰레드들은 일반적으로 무한 루프를 돌면서 작업을 가져오기 위해 대기합니다.
4. 작업 처리: 쓰레드 풀의 스레드가 작업을 가져와서 처리합니다. 작업은 일반적으로 작업 큐에서 FIFO(선입선출) 방식으로 가져오게 됩니다.
5. 작업 완료 및 반환: 작업이 완료되면 해당 결과를 반환하고, 스레드는 다시 작업 큐에서 새로운 작업을 가져오기 위해 대기 상태로 돌아갑니다.
6. 작업 대기: 작업 큐에 새로운 작업이 추가되면 쓰레드 풀의 스레드들은 대기 상태를 벗어나 작업을 가져와 처리합니다. 이를 반복하여 계속적으로 작업을 수행합니다.
7. 종료: 쓰레드 풀을 더 이상 사용하지 않을 때 종료합니다. 종료할 때는 모든 작업이 완료되었는지 확인하고, 필요에 따라 남은 작업들을 처리하거나 버릴 수 있습니다.
쓰레드 풀을 사용하는 이유
1. 프로그램 성능 저하를 방지하기 위해
2. 다수의 사용자 요청을 처리하기 위해
쓰레드 풀의 장단점
쓰레드 풀의 장점
- 스레드를 생성/수거하는데 비용이 들지 않습니다.
- 스레드가 생성될 때 OS가 메모리 공간을 확보해주고 메모리를 쓰레드에게 할당해줍니다.
- 스레드 풀을 미리 만들어 두기 때문에 처음에 생성하는 비용은 들지만 이전의 쓰레드를 재사용할 수 있으므로 시스템 자원을 줄일 수 있고, 작업을 요청 시 이미 쓰레드가 대기 중인 상태이기 때문에 작업을 실행하는 데 딜레이가 발생하지 않습니다.
쓰레드 풀의 단점
- thread pool에 thread를 너무 많이 생성해 두었다가 사용하지 않으면 메모리 낭비가 발생합니다.
- Thread pool의 단점 개선 : **Fork Join Thread Pool**

BD 데이터 베이스 구조
-파일 시스템 VS 데이터베이스
파일 시스템은
- 개별적인 파일들을 보관하고 정리하는 데 사용되는 **큰 창고**와 같습니다.
- 파일들은 여러 폴더에 저장되고, 사용자는 파일을 직접 관리해야 합니다.
- 이 비유에서는 사람들이 파일들을 개별적으로 처리하고 정리하는 데 많은 시간과 노력을 투자해야 한다고 할 수 있습니다.
데이터베이스는
- 체계적으로 구성된 도서관으로 비유할 수 있습니다.
- 데이터베이스는 파일 시스템과는 다르게 데이터를 구조화하고 연결시키는 기능을 제공합니다.
- 데이터베이스는 테이블, 레코드, 필드 등의 개념을 사용하여 데이터를 구성하고, 데이터를 효율적으로 관리하고 검색할 수 있습니다.
- 데이터베이스 시스템은 도서관리 시스템과 비슷한 역할을 합니다.
- 데이터베이스 시스템을 사용하면 데이터의 일관성, 무결성, 안전성을 유지하며 복잡한 데이터 조작 작업을 간편하게 수행할 수 있습니다.
- 파일 시스템의 단점
- 다수의 사용자들을 위한 동시성 제어가 제공되지 않음
- 검색하려는 데이터를 쉽게 명시하려는 질의어가 제공되지 않음.
- 보안 조치가 미흡
- 회복 기능이 없음.
- 프로그램-데이터 독립성이 없으므로 유지보수 비용이 많이 소요됨.
- 파일을 검색하거나 갱신하는 절차가 상대적으로 복잡하기 때문에 프로그래머의 생산성이 낮음.
- DBMS의 장점
- 스키마 정의를 통해
- 중복성과 불일치가 감소됨
- 표준화를 시행하기가 용이
- 조직체의 요구사항을 식별할 수 있음
- 관리도구를 통해
- 시스템을 개발하고 유지하는 비용이 감소됨.
- 보안이 향상됨
- 무결성이 향상됨
- 다양한 유형의 고장으로부터 데이터베이스를 회복할 수 있음.
- 데이터베이스의 공유와 동시 접근이 가능함.
- 스키마 정의를 통해
- DBMS의 단점
- 추가적인 하드웨어 구입 비용이 들고, DBMS 자체의 구입 비용도 상당히 비쌈.
- 직원들의 관리도구 사용법 교육 비용 많이 소요됨
- 비밀과 프라이버시 노출 등의 단점이 존재할 수 있음
💁 DBMS를 적용하면 안되는 경우
- 초기의 투자 비용이 너무 클 때
- 오버헤드가 너무 클 때
- 응용이 단순하고 잘 정의되었으며 변경되지 않을 것으로 예상될 때
- 엄격한 실시간 처리 요구사항이 있을 때
- 데이터에 대한 다수 사용자의 접근이 필요하지 않을 때
DBMS 발전 과정
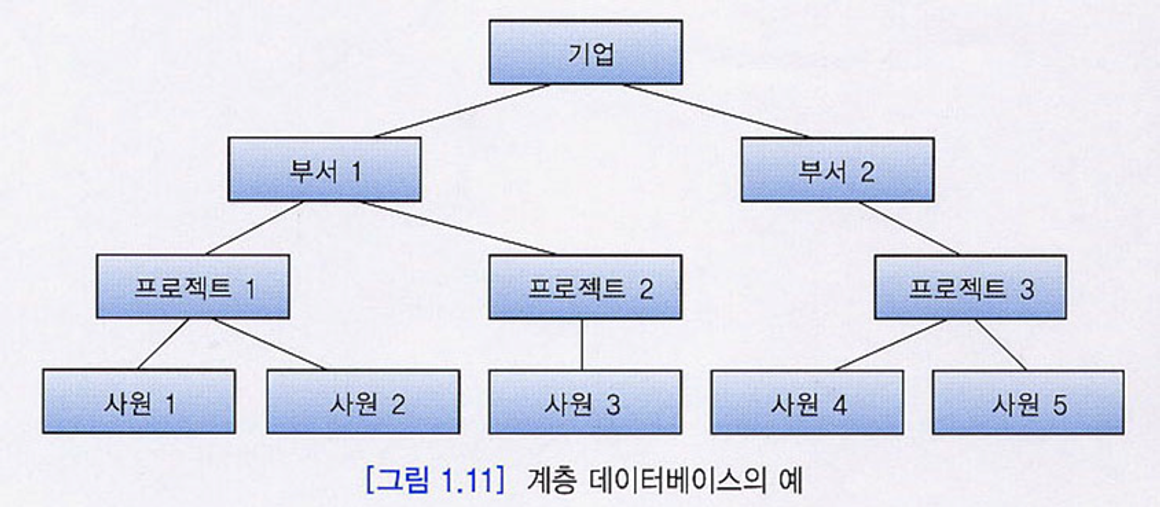
1) 계층 DBMS 구조
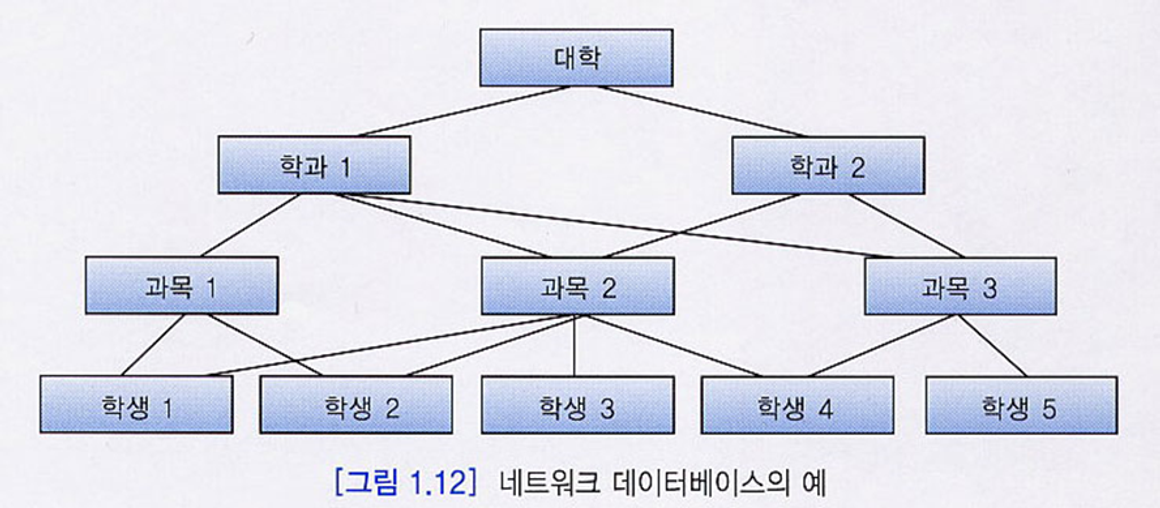
2) 네트워크 DBMS 구조
3) 관계 DBMS (가장 많이 쓰임)
예 : MS SQL Server, Oracle, Sybase, DB2, MySQL
4) 객체 지향 DBMS
- 특징
- 객체 지향 프로그래밍 패러다임을 기반으로 하는 데이터 모델
- 장점
데이터와 프로그램을 그룹화하고, 복잡한 객체들을 이해하기 쉬우며, 유지와 변경이 용이함.
- 예 : ONTOS, OpenODB, GemStone, ObjectStore, O2 등
5) 객체 관계 DBMS
- 특징
- DBMS에 객체 지향 개념을 통합한 객체 관계 데이터 모델이 제안됨.
- 예 : 오라클, Informix, Universal Server 등

점점 갈수록 프로그래머가 할 분량이 DBMS에서 작동을 하기에 편리해 진다.
관계형 데이터 베이스 (SQL)

- 특징
- 바탕이 되는 데이터 구조로서 간단한 테이블(릴레이션)을 사용
- 중첩된 복잡한 구조가 없음
- 집합 위주로 데이터를 처리
- 숙련되지 않은 사용자도 쉽게 이해할 수 있음
- 표준 데이터베이스 응용에 대해 좋은 성능을 보임
- 기본적인 용어
- 릴레이션(relation) : 2차원의 테이블(스프레드 시트와 유사)
- 레코드(record) : 릴레이션의 각 행
- 튜플(tuple) : 레코드를 좀 더 공식적으로 부르는 용어 = 로우(row)
- 속성(attribute) : 릴레이션에서 이름을 가진 하나의 열 = 컬럼(column)

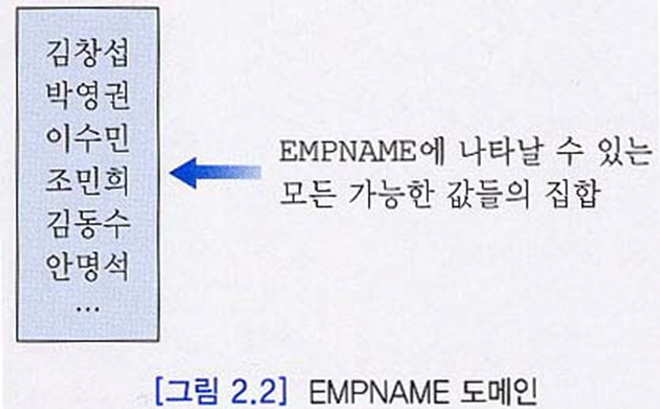
- 도메인(domain)
- 한 속성에 나타날 수 있는 값들의 집합
- 각 속성의 도메인의 값들은 원자값
- 동일한 도메인이 여러 속성에서 사용될 수 있음
- ex. EMPNAME 의 도메인 정의

- 차수(degree)와 카디날리티(cardinality)
- 차수 : 한 릴레이션에 들어 있는 속성들의 수(필드 수) = 세로 개수
- 유효한 릴레이션의 최소 차수는 1
- 속성이 1개이상 있어야 릴레이션(테이블)이 됩니다.
- 릴레이션의 차수는 자주 바뀌지 않음.
- 보통 테이블 스키마는 자주 못바꿉니다.
- 스키마 변경시 전체 로우에 반영되어야 하기 때문에 처리가 중단됩니다.
- 유효한 릴레이션의 최소 차수는 1
- 카디날리티 : 릴레이션의 튜플(로우 수) = 가로 개수
- 유효한 릴레이션은 카디날리티 0을 가질 수 있음.
- 릴레이션의 카디날리티는 시간이 지남에 따라 계속해서 변함.
- 차수 : 한 릴레이션에 들어 있는 속성들의 수(필드 수) = 세로 개수
비관계형 데이터베이스 (NoSQL)
문서형(Document) 데이터베이스
대표적인 문서형 데이터베이스에는 MongoDB
Key-Value 타입
Redis, Dynamo 등이 대표적인 Key-Value 형식의 데이터베이스
Wide-Column Store 데이터베이스
대표적인 wide-column 데이터베이스에는 Cassandra, HBase
그래프(Graph) 데이터베이스
대표적인 그래프 데이터베이스에는 Neo4J, InfiniteGraph
- 장점
- 대용량 데이터 처리를 하는데 효율적임.
- 읽기 작업보다 쓰기 작업이 더 빠르고 관계형 데이터베이스에 비해 쓰기와 읽기 성능이 빠름.
- 데이터 모델링이 유연함.
- 뛰어난 확장성으로 검색에 유리함.
- 최적화된 키 값 저장 기법을 사용하여 응답속도나 처리효율 등에서 성능이 뛰어남.
- 복잡한 데이터 구조를 표현할 수 있음.
- 단점
- 쿼리 처리시 데이터를 파싱 후 연산을 해야해서 큰 크기의 document를 다룰 때는 성능이 저하됨.
'코딩 교육 TIL' 카테고리의 다른 글
| 2024-03-20 AI 코딩 TIL (0) | 2024.03.20 |
|---|---|
| 2024-03-19 AI 코딩 TIL (0) | 2024.03.19 |
| 2024 -03-15 AI 코딩 TIL (4) | 2024.03.15 |
| 2024-03-14 AI 코딩 TIL (5) | 2024.03.14 |
| 2024-03-13 AI 코딩 TIL (0) | 2024.03.13 |
이번주부터는 cs에 대해서 공부를 시작합니다!
CPU와 메모리
우리가 사용하는 컴퓨터의 구조를 일상생활에 비교를 해보자!
푸드 트럭
컴퓨터
컴퓨터에는 입력장치 출력장치 기억장치 연산장치 등등이 있습니다.
입력장치
마우스 키보드 카메라
출력장치
스피커 모니터 등등
cpu의 구성
사람의 두뇌에 해당되는 cpu의 구성이다.
cpu안에서도 산술 논리를 위한 (ALU), 제어(CU)를 위한 버스, 메모리 유닛으로 레지스터와 캐시가 있습니다.
프로세서에 위치한 고속 메모리로 극히 소량의 데이터나 처리 중인 중간 결과와도 같은 프로세서가 바로 사용할 수 있는 데이터를 담고 있는 영역을 레지스터라고 한다. 컴퓨터 구조에 따라 크기와 종류가 다양하다. 용도에 따라 범용 레지스터와 특수목적 레지스터로 구분된다
범용 레지스터 : 연산에 필요한 데이터나 연산 결과를 임시로 저장한다. 특수목적 레지스터 : 특별한 용도로 사용하는 레지스터이다
✅ 특수목적 레지스터는 아래와 같은 다양한 레지스터가 존재합니다.
- 메모리 주소 레지스터: (MAR) : 읽고 쓰기 위한 주기억장치의 주소를 저장한다.
- 프로그램 카운터 (PC) : 다음에 수행할 명령어의 주소를 저장
- 명령어 레지스터 (IR) : 현재 실행 중인 명령어를 저장
- 메모리 버퍼 레지스터 (MBR) : 주기억장치에서 읽어온 데이터나 저장할 테이터를 임시로 저장
- 누산기 (AC, ACCUMULATOR) : 연산 결과를 임시로 저장
컴퓨터의 성능에서 가장 중요한 부분인 CPU의 성능은 클럭과 코어로 표현할 수 있다.
메모리
- 레지스터 = CPU
- 캐시메모리(SRAM), 메인 메모리(DRAM) = 주 기억장치
- 하드디스크(HDD) = 보조 기억장치
레지스터는 연산을 위한 데이터 공간
캐시는 잠깐두는 곳
주기억장치(RAM)는? DRAM과 SRAM이 있는데
SRAM은 캐시와 레지스트리를 의미하고
우리가 일반적으로 알고 있는 램은 DRAM에 속한다.
간단하게 느낌을 보자면 하드와 CPU 간에 속도 차이를 위해서 있는 것이 DRAM이고 그 DRAM과 CPU 간의 속도차이를 위해서 있는 것이 SRAM인 것 같습니다.
CPU와 메모리의 구조는 하버드 구조와 폰노이만 구조가 있습니다!
즉 데이터를 얼마나 빠르게 전달하는지가 성능에 중요하다고 할 수 있습니다!
CPU심화
프로세스와 스레드
카카오톡을 실행시키는 프로세스
메시지를 발송처리하는 스레드
오버헤드 : 프로세스가 필요한 자원보다 더 많이 사치를 부리는 것
사용률 : 프로세스가 최대한 자원을 많이 받고 빨리 처리하는 것
기아 현상 : 프로세스가 자원할당을 못 받아서 배고픈 상태
CPU , I/O Burst Cycle
- 프로세스 실행은 “CPU실행 ↔ 입/출력 대기” 의 반복을 의미합니다.
- CPU Burst
- 프로세스의 사용 중에 연속적으로 CPU를 사용하는 구간을 의미합니다.
- 즉, 실제 CPU를 사용하는 스케쥴링의 단위이다.
- I/O Burst
- 프로세스의 실행 중에 I/O작업이 끝날 때까지 Block 되는 구간을 의미합니다.
스케쥴링은 OS가 CPU를 사용권을 선점하나 아니냐에 따라 선점/비선점으로 나뉜다.
선점 스케쥴링(Preemptive Scheduling)
선점 1.Priority Scheduling(우선순위 스케쥴링)
우선순위가 빠른 순으로 진행이 된다.
하지만 우선순위가 낮은 프로세스의 경우 무한 대기를 할 수 있다.
선점 2.Round Robin(라운드로빈)
각 프로세스를 실행할 때에 시간마다 나누어서 실행을 한다.
우선순위가 낮을 경우 사용을 하면 골고루 배치가 가능하나
프로세스 간의 전환(=문맥전환)이 자주 일어나서 시간낭비가 있다.
선점 3.Multilevel-Queue(다단계 큐)
준비완료 큐를 여러 개의 큐로 분류하여 각 큐가 각각 다른 스케쥴링 알고리즘을 가지는 방식. 메모리 크기, 우선순위, 유형 등 프로세스의 특성에 따라 하나의 큐에 영구적으로 할당된다. 따라서 큐와 큐 사이에도 스케쥴링이 필요하다. 우선순위 방식 혹은 시분할 방식으로 한다.
우선순위 방식
고정 우선순위의 선점형 방식으로 구현되며, 따라서 우선순위에 따른 큐의 스케쥴링은 절대적이다. 예를 들어,
우선순위가 높은 Forground Queue
- 대화형 프로세스를 위한 큐
- Round Robin
우선순위가 낮은 Background Queue
- 연산작업을 처리하는 프로세스 큐
- FCFS
여기서 Forground큐가 비어있지 않는 한 Background큐는 먼저 실행될 수 없으며, Background큐가 먼저 실행 중이더라도 Forground큐에 프로세스가 들어오면 선점된다.
비선점 스케쥴링(Non-Preemptive Scheduling)
처리시간 예측에 용이합니다.
긴 처리시간의 프로세스를 만나면 다른 프로세스를 대기시킬 수 있으므로 처리율이 떨어질 수 있다는 단점이 있습니다.
비선점 1. FCFS (First Come , First Serve)
계산대처럼 앞에 많은 시간을 기다려야 하면 짧은 처리프로세스를 가지고 있어도 앞에 프로세스가 끝날 때까지 대기를 해야 한다는 단점이 존재
다른 방식에도 FCFS라는 단어가 많이 보이는데 간단하게 먼저 들어온 프로세스가 먼저 처리가 된다는 의미이며 기본적인 구조 방식으로 특정 조건이 성립되지 않는 한 이 규칙을 기본으로 잡고 실행을 합니다.
비선점 2. SJF(Shorted Job First)
수행시간이 짧다고 판단이 되는 프로세스부터 먼저 수행을 한다.
가장 적은 평균대기시간을 처리
비선점 3. HRN (Highest Response-ratio Next)
💡 HRN 특징
- 우선순위를 계산하여 점유 불평등 보완(SJF 단점 보완)
- 우선순위 = (대기시간 + 실행시간) / (실행시간)
지역성??
지속적인 반복작업을 진행할 때 빠르게 값을 가져올 수 있도록 하는 것
지역성에는 시간지역성과 공간지역성이 있습니다
시간 지역성
최근 사용한 데이터에 다시 접근하려는 특성
ex) for문 안에 선언된 i는 반복문 안에서 계속해서 접근이 이루어지는 변수이다. 최근에 사용했기 때문에 계속 접근해서 +1 이 이루어지는 것이다. (i 변수에 대한 시간 지역성)
for(let i=0; i<5; i++){
console.log(i) // 0 1 2 3 4
}공간 지역성
최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성
ex) 배열 arr이라는 공간에 i가 연속적으로 할당되어 접근하는 방식 (arr 배열 원소에 대한 공간 지역성)
let arr = [];
for(let i=0; i<5; i++){
arr.push(i)
}
// arr = [0,1,2,3,4]
페이지 교체 알고리즘
프로세스와 스레드
내 컴퓨터의 작업관리자를 보면 사용 중인 프로세스를 볼 수 있습니다
CPU의 상태를 보면 프로세스의 수와 스레드의 사용량을 볼 수 있습니다.
프로세스 생명주기
📌 프로세스 상태변화 = 프로세스 생명주기
프로세스 생명주기와 프로세스 상태변화는 같은 의미입니다.
- 🟠은 프로세스들의 상태를 의미하고
- 🔜 은 스케쥴링에 따라 상태가 변화되는 동작을 의미합니다.
- 상태변화 = 생명주기
신규 - 준비 - 수행 - 대기 OR 종료
📌 수행상태에서 해제되는 경우 예시
- 수행 -> 준비(중단)
- CPU의 과부하가 판단되는 경우
- 수행 -> 대기
- I/O 나 event wait가 있을 경우
- 이 후 I/O나 evet가 끝나면 ready 상태로 복구
대기 큐 (Waiting Queue)
잡 큐 : 하드 -> 메모리로 갈 때 메모리가 가득 차면 잠시 하드에서 대기를 하는 공간
레디 큐 : 메모리 -> CPU 갈 때 대기 하는 큐
디바이스 큐 : CPU -> 입출력 장치 위와 동일하게 대기하는 큐 (프린터, 마우스... 등등)
큐 스케쥴링
**Job Scheduler :**
- Job Queue의 프로그램들을 어떤 순서로 메모리에 올릴 것인지 결정합니다.
- 이러한 과정은 프로그램이 새로 시작될 때, 메인메모리가 가득 찬 경우 등의 상황에만 발생하므로 자주 일어나지 않고 어쩌다 한번(수분 ~ 수십 분) 일어납니다.
📌 Long Term Scheduler
프로그램이 새로 시작될 때, 메인메모리가 가득찬 경우 등의 상황에만 발생하므로 자주 일어나지 않고 어쩌다 한번(수분 ~ 수십분) 일어나며, 이처럼 긴 간격으로 동작하는 스케줄러를 Long Term Scheduler라고 합니다
**CPU Scheduler :**
- Ready Queue의 프로세스들을 어떤 순서로 서비스할 것인지에 대한 스케줄러입니다.
- 모든 스케줄링 중에서 CPU 스케줄링이 가장 중요합니다.
📌 Short Term Scheduler
- 시공유 시스템의 경우 이러한 과정은 1초에도 수십번에서 많게는 수백번도 일어나기 때문에 이러한 스케줄러를 Short Term Scheduler라고 합니다.
**Device Scheduler :**
- Device Queue의 프로세스들을 어떤 순서로 I/O 장치를 이용하게 할 것인지에 대한 스케줄러입니다.
- 이는 Disk Scheduler, Printer Scheduler, Mouse Scheduler 등 I/O, 보조기억 장치 스케줄러를 통틀어 가리키는 말입니다.
📌 I/O Bound Process VS CPU Bound Process
- I/O Bound Process
- 대부분의 시간을 I/O하는데 쓰는 프로세스들을 의미합니다.
- CPU Bound Process
- 대부분의 시간을 CPU로 연산하는데 쓰는 프로세스를 의미합니다.
✅ 운영체제(Job Scheduler)는 이들을 적절하게 배합하여 I/O 장치와 CPU 모두 너무 오랫동안 쉬게 하지 않아야 합니다. (성능을 위해)
**주-보조 교환 (Swapping)**
**1) Swapping :**
- 서버와 같이 여러 사용자가 하나의 메모리를 공유하는 경우에 만약 한 사용자가 자리를 비우면 그 사용자가 돌아올 때까지 해당 프로세스에 메모리를 할당할 이유가 없습니다! 😱
- 때문에 PCB(Process Control Block)의 CPU Time 등을 확인해서 오랫동안 동작이 없는 프로세스는 잠시 HDD로 내려놓고, 다른 프로세스를 실행하거나 기존 프로세스에 메모리를 더 할당하는 등 메모리를 더 효율적으로 활용합니다.
- 그러다가 동작 없던 프로세스 사용자가 돌아와서 작업을 수행하면 다시 HDD에서 메모리로 프로세스를 올립니다.
- **Swap Out**
- 메모리에서 HDD로 내리는 작업
- **Swap In**
- HDD에서 다시 메모리로 올리는 작업
- 이렇게 임시 메모리의 목적으로 사용되는 HDD 공간을 Backing Store 혹은 Swap Device라고 합니다.
📌 medium Term Scheduler
- Swapping 역시 여러 프로세스들이 HDD로 내려가고 다시 메모리로 올라오고 하기 때문에 어떤 순서로 프로세스를 먼저 내리고 올릴지 결정해야합니다.
- 이러한 스케줄링 작업은 Short Term Scheduling 보다는 적게 일어나지만 Long Term Scheduling 보다는 자주 일어납니다.
- 때문에 이러한 스케줄링 작업(Swapping Scheduling)을 Midium Term Scheduling이라고 합니다.
오... 컴퓨터를 쓰면 메모리 확장을 위해서 스왑기능을 활성화하는 경우를 자주 보았는데 원리가 이런 원리였는지는 오늘 알았습니다.
그냥 하드디스크의 일부를 메모리처럼 쓰는 줄 알았는데 메모리에서 넘치는 부분은 잠시 보관하는 용도였을 줄이야..
문맥 교환 (Context Switching)
CPU가 프로세스를 처리할 때 시간마다 돌아가면서 동작을 하는데 속도가 엄청 빠르기 때문에 우리가 보기에는 동시에 작업이 진행이 되는 것처럼 보입니다.
프로세스 메모리
위아래 동일한 그림
1) Code 영역
- 실행할 프로그램의 코드가 저장됩니다. CPU는 이 영역에서 명령어를 하나씩 가져와 처리하게 됩니다.
2) Data 영역
- 전역변수와 정적변수가 저장됩니다.
- 이 변수들은 프로그램이 시작될 때 할당되어 프로그램 종료 시 소멸됩니다.
- BSS(Block Stated Symbol) 영역?
- BSS 영역에는 초기화 되지 않은 전역변수가 저장됩니다.
- 초기화 된 전역변수는 Data 영역에 저장되어 비휘발성 메모리인 ROM에 저장되는데 이 부분은 비용이 많이 들어 RAM에 저장될 것과 ROM에 저장될 것을 구분하기 위해 영역을 구분해 사용합니다.
3) Stack 영역
- 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터(지역변수, 매개변수, 리턴값 등)를 임시로 저장하는 공간
- 이 영역은 함수 호출시 기록하고 함수의 수행이 완료되면 사라진다. 메커니즘은 자료구조(stack)에서 배운 LIFO(Last In First Out) 방법으로 저장/출력 합니다.
- 컴파일 시 stack 영역의 크기가 결정되기 때문에 무한정 할당 할 수 없습니다.
- 따라서 재귀함수가 반복해서 호출되거나 함수가 지역변수를 메모리를 초과할 정도로 너무 많이 가지고 있다면 stack overflow가 발생합니다. (알고리즘 시험풀때 많이 발생!)
위 세 영역은 컴파일할 때 data, stack 영역의 크기를 계산해 메모리 영역을 결정합니다!
4) Heap 영역
- 동적 데이터 영역입니다.
- 메모리 주소 값에 의해서만 참조되고 사용되는 영역입니다. 따라서, 프로그램 동작 시(런타임)에 크기가 결정됩니다.
- 예를 들어, stack에서 pointer 변수를 할당하면 pointer가 가리키는 heap 영역의 임의의 공간부터 원하는 크기만큼 할당해 사용하게 됩니다.
- heap 영역은 런타임에 결정된다. 자바에서는 객체가 heap영역에 생성되고 GC에 의해 정리됩니다.
- GC 는 Garbage Collector 의 약자로, 안쓰는 heap 영역을 치우는 쓰레기 청소부👷♀️입니다.
커널 프로세스의 메모리
커널은 명령을 즉시 실행할 수 있는 인터프리터 역할을 한다.
컴퓨터 상에서 프로그램 강제 종료 같은 걸 할 수 있는 역할
커널은 CODE, DATA, STACK이 있고 HEAP은 없습니다.
✅ 정리하기
1) 프로세스 : 메모리에 올라온 프로그램
2) 프로세스 생명주기 : 신규 - 준비 - 수행 - 대기 - 종료
3) PCB : 프로세스의 실행 정보와 상태 정보를 저장하는 자료구조 (PID, PC, Register, MMU 등)
4) 대기 큐 (Queue) : Job, Ready, Device Queue 등
5) Scheduler : Job, CPU, Device Schduler 등
6) Swapping : 안 쓰는 프로세스 HDD로 내리고, 다시 쓰이면 메모리로 올리는 작업
7) Context Switching : Running 프로세스를 Ready로 만들고 다른 프로세스로 전환
8) Dispatcher : 콘텍스트 스위칭할 때 필요한 정보(PCB를 저장하고 꺼내는 프로그램)
9) CPU 시간공유 시스템 : (대부분의) OS에서 프로세스(스레드)가 시간단위로 나누어서 CPU를 사용할 수 있도록 관리해 주는 시스템
10) 프로세스 메모리 공간 : 프로세스 주소 공간은 Code, Data, Stack, Heap으로 구성됨
11) 커널 : 커널은 대부분의 운영 체제(OS)의 주요 구성 요소이며 컴퓨터 하드웨어와 프로세스를 잇는 핵심 인터페이스
12) PCB : 프로세스의 실행 정보와 상태 정보를 저장하는 자료구조로 커널 프로세스에 존재
스레드
스레드와 프로세스의 차이점
프로세스 안에 스레드가 있지만 하는 역할이 조금 다릅니다.
스레드는 프로세스 내에서 실행되는 실행 단위이며, 쓰레드 풀은 쓰레드를 미리 생성해 두어 작업 처리에 사용되는 쓰레드를 제한된 개수만큼 정해 놓고 작업 큐에 들어오는 작업들을 하나씩 쓰레드가 맡아 처리하는 기법입니다.
프로그램을 실행하는 주체 = 프로세스
(예시 = 치킨집)
작업을 처리하는 주체 = 쓰레드
(예시 = 치킨집 직원)
치킨집 안에 공간과 재료를 같이 쓴다 = 자원 공유
모든 프로세스 안에는 스레드가 한 개이상이 있어야 한다.
프로세스의 구성으로는 CODE, DATA, HEAP, STACK이 있으며 이 것을 공유한다.
만약에 프로세스로만 작업을 한다면???
1. 프로세스만으로 작업하면 시간이 많이 소요가 됩니다.
2. 프로세스 사이에 통신이 어렵습니다.
3. 생성에 오버헤드 많음
쓰레드 프로세스로부터 공유를 받으면 개별적으로 STACK만을 가지고 있습니다.
이로 인하여 작은 단위에 실행이 구현이 되며
생성 및 소멸의 오버헤드가 감소
스레드 간 자원 공유로 빠른 스위칭 가능
프로세스들의 통신 어려움 해소
프로세스는 다음의 특징을 갖습니다.
- 각각 독립된 메모리 영역(Code, Data, Stack, Heap)을 할당받습니다.
- 코드 영역(code area): 프로그래머가 작성한 프로그램이 저장되는 영역
- 데이터 영역(data area): 코드가 실행되면서 사용한 환경이나 파일들의 각종 데이터들이 모여있습니다.
- 스택 영역(stack area): 호출한 함수가 종료되면 되돌아올 메모리의 주소나 지역 변수 등이 저장됩니다.
- 힙 영역(heap area): 동적으로 할당되는 데이터를 위해 존재합니다.
📌 치킨집에서 각자 일하는 공간(Stack)이 있지만,
- 업무 메뉴얼(Code)도 같이 보고
- 손님의 주문(Data)도 같이 받고
- 손님이 주문한 치킨을 서빙 하는 홀 공간(Heap)도 같이 쓴다는 점과 비슷합니다.
👌 **멀티 프로세스 대신 멀티 스레드를 사용하는 이유**
**`자원 효율성 증대`, `처리 비용 감소`, `응답 시간 단축`**
쓰레드 풀
- 컴퓨터 프로그래밍에서 쓰레드 풀은 컴퓨터 프로그램에서 실행의 동시성을 달성하기 위한 소프트웨어 디자인 패턴입니다.
- 프로그램이 작업을 동시에 실행할 수 있도록 여러 스레드를 미리 생성해 두고 유지 관리합니다.
- 여러 Thread를 동시에 만들어 실행(병렬처리)할 수 있습니다.
- 🤫 그렇다고 해서 Thread를 계속 늘려가는 건 좋은 것일까? 당연히 아닙니다.
하드웨어의 제한적인 사항(CPU, Memory 등)이 있기 때문에 관리할 필요가 있습니다.
그래서 스레드 풀 이라는 개념을 이용합니다.
- 쓰레드 풀은 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해 놓고 작업 큐(Queue)에 들어오는 작업들을 하나씩 스레드가 맡아 처리하는 것을 말합니다.
- 치킨집에서 직원 뽑기가 어려우니 직원들을 미리 뽑아두는 것과 비슷합니다.
해야 할 일을 순서대로(작업 큐) 직원들에게 할당해주며 처리하도록 합니다.
💁 **스레드 풀의 동작**
1. 초기화: 쓰레드 풀을 사용하기 전에 초기화해야 합니다. 이 단계에서는 쓰레드 풀의 크기, 최대 쓰레드 수, 작업 큐 등의 매개변수를 설정합니다.
2. 작업 수신: 쓰레드 풀은 작업을 수신하고 처리할 준비를 합니다. 작업은 일반적으로 작업 큐에 추가됩니다.
3. 작업 수행: 스레드 풀에서는 미리 생성된 쓰레드들이 작업 큐를 모니터링하고 대기 중인 작업을 가져와 처리합니다. 이때 쓰레드 풀 내의 쓰레드들은 일반적으로 무한 루프를 돌면서 작업을 가져오기 위해 대기합니다.
4. 작업 처리: 쓰레드 풀의 스레드가 작업을 가져와서 처리합니다. 작업은 일반적으로 작업 큐에서 FIFO(선입선출) 방식으로 가져오게 됩니다.
5. 작업 완료 및 반환: 작업이 완료되면 해당 결과를 반환하고, 스레드는 다시 작업 큐에서 새로운 작업을 가져오기 위해 대기 상태로 돌아갑니다.
6. 작업 대기: 작업 큐에 새로운 작업이 추가되면 쓰레드 풀의 스레드들은 대기 상태를 벗어나 작업을 가져와 처리합니다. 이를 반복하여 계속적으로 작업을 수행합니다.
7. 종료: 쓰레드 풀을 더 이상 사용하지 않을 때 종료합니다. 종료할 때는 모든 작업이 완료되었는지 확인하고, 필요에 따라 남은 작업들을 처리하거나 버릴 수 있습니다.
쓰레드 풀을 사용하는 이유
1. 프로그램 성능 저하를 방지하기 위해
2. 다수의 사용자 요청을 처리하기 위해
쓰레드 풀의 장단점
쓰레드 풀의 장점
- 스레드를 생성/수거하는데 비용이 들지 않습니다.
- 스레드가 생성될 때 OS가 메모리 공간을 확보해주고 메모리를 쓰레드에게 할당해줍니다.
- 스레드 풀을 미리 만들어 두기 때문에 처음에 생성하는 비용은 들지만 이전의 쓰레드를 재사용할 수 있으므로 시스템 자원을 줄일 수 있고, 작업을 요청 시 이미 쓰레드가 대기 중인 상태이기 때문에 작업을 실행하는 데 딜레이가 발생하지 않습니다.
쓰레드 풀의 단점
- thread pool에 thread를 너무 많이 생성해 두었다가 사용하지 않으면 메모리 낭비가 발생합니다.
- Thread pool의 단점 개선 : **Fork Join Thread Pool**
BD 데이터 베이스 구조
-파일 시스템 VS 데이터베이스
파일 시스템은
- 개별적인 파일들을 보관하고 정리하는 데 사용되는 **큰 창고**와 같습니다.
- 파일들은 여러 폴더에 저장되고, 사용자는 파일을 직접 관리해야 합니다.
- 이 비유에서는 사람들이 파일들을 개별적으로 처리하고 정리하는 데 많은 시간과 노력을 투자해야 한다고 할 수 있습니다.
데이터베이스는
- 체계적으로 구성된 도서관으로 비유할 수 있습니다.
- 데이터베이스는 파일 시스템과는 다르게 데이터를 구조화하고 연결시키는 기능을 제공합니다.
- 데이터베이스는 테이블, 레코드, 필드 등의 개념을 사용하여 데이터를 구성하고, 데이터를 효율적으로 관리하고 검색할 수 있습니다.
- 데이터베이스 시스템은 도서관리 시스템과 비슷한 역할을 합니다.
- 데이터베이스 시스템을 사용하면 데이터의 일관성, 무결성, 안전성을 유지하며 복잡한 데이터 조작 작업을 간편하게 수행할 수 있습니다.
- 파일 시스템의 단점
- 다수의 사용자들을 위한 동시성 제어가 제공되지 않음
- 검색하려는 데이터를 쉽게 명시하려는 질의어가 제공되지 않음.
- 보안 조치가 미흡
- 회복 기능이 없음.
- 프로그램-데이터 독립성이 없으므로 유지보수 비용이 많이 소요됨.
- 파일을 검색하거나 갱신하는 절차가 상대적으로 복잡하기 때문에 프로그래머의 생산성이 낮음.
- DBMS의 장점
- 스키마 정의를 통해
- 중복성과 불일치가 감소됨
- 표준화를 시행하기가 용이
- 조직체의 요구사항을 식별할 수 있음
- 관리도구를 통해
- 시스템을 개발하고 유지하는 비용이 감소됨.
- 보안이 향상됨
- 무결성이 향상됨
- 다양한 유형의 고장으로부터 데이터베이스를 회복할 수 있음.
- 데이터베이스의 공유와 동시 접근이 가능함.
- 스키마 정의를 통해
- DBMS의 단점
- 추가적인 하드웨어 구입 비용이 들고, DBMS 자체의 구입 비용도 상당히 비쌈.
- 직원들의 관리도구 사용법 교육 비용 많이 소요됨
- 비밀과 프라이버시 노출 등의 단점이 존재할 수 있음
💁 DBMS를 적용하면 안되는 경우
- 초기의 투자 비용이 너무 클 때
- 오버헤드가 너무 클 때
- 응용이 단순하고 잘 정의되었으며 변경되지 않을 것으로 예상될 때
- 엄격한 실시간 처리 요구사항이 있을 때
- 데이터에 대한 다수 사용자의 접근이 필요하지 않을 때
DBMS 발전 과정
1) 계층 DBMS 구조
2) 네트워크 DBMS 구조
3) 관계 DBMS (가장 많이 쓰임)
예 : MS SQL Server, Oracle, Sybase, DB2, MySQL
4) 객체 지향 DBMS
- 특징
- 객체 지향 프로그래밍 패러다임을 기반으로 하는 데이터 모델
- 장점
데이터와 프로그램을 그룹화하고, 복잡한 객체들을 이해하기 쉬우며, 유지와 변경이 용이함.
- 예 : ONTOS, OpenODB, GemStone, ObjectStore, O2 등
5) 객체 관계 DBMS
- 특징
- DBMS에 객체 지향 개념을 통합한 객체 관계 데이터 모델이 제안됨.
- 예 : 오라클, Informix, Universal Server 등
점점 갈수록 프로그래머가 할 분량이 DBMS에서 작동을 하기에 편리해 진다.
관계형 데이터 베이스 (SQL)
- 특징
- 바탕이 되는 데이터 구조로서 간단한 테이블(릴레이션)을 사용
- 중첩된 복잡한 구조가 없음
- 집합 위주로 데이터를 처리
- 숙련되지 않은 사용자도 쉽게 이해할 수 있음
- 표준 데이터베이스 응용에 대해 좋은 성능을 보임
- 기본적인 용어
- 릴레이션(relation) : 2차원의 테이블(스프레드 시트와 유사)
- 레코드(record) : 릴레이션의 각 행
- 튜플(tuple) : 레코드를 좀 더 공식적으로 부르는 용어 = 로우(row)
- 속성(attribute) : 릴레이션에서 이름을 가진 하나의 열 = 컬럼(column)
- 도메인(domain)
- 한 속성에 나타날 수 있는 값들의 집합
- 각 속성의 도메인의 값들은 원자값
- 동일한 도메인이 여러 속성에서 사용될 수 있음
- ex. EMPNAME 의 도메인 정의
- 차수(degree)와 카디날리티(cardinality)
- 차수 : 한 릴레이션에 들어 있는 속성들의 수(필드 수) = 세로 개수
- 유효한 릴레이션의 최소 차수는 1
- 속성이 1개이상 있어야 릴레이션(테이블)이 됩니다.
- 릴레이션의 차수는 자주 바뀌지 않음.
- 보통 테이블 스키마는 자주 못바꿉니다.
- 스키마 변경시 전체 로우에 반영되어야 하기 때문에 처리가 중단됩니다.
- 유효한 릴레이션의 최소 차수는 1
- 카디날리티 : 릴레이션의 튜플(로우 수) = 가로 개수
- 유효한 릴레이션은 카디날리티 0을 가질 수 있음.
- 릴레이션의 카디날리티는 시간이 지남에 따라 계속해서 변함.
- 차수 : 한 릴레이션에 들어 있는 속성들의 수(필드 수) = 세로 개수
비관계형 데이터베이스 (NoSQL)
문서형(Document) 데이터베이스
대표적인 문서형 데이터베이스에는 MongoDB
Key-Value 타입
Redis, Dynamo 등이 대표적인 Key-Value 형식의 데이터베이스
Wide-Column Store 데이터베이스
대표적인 wide-column 데이터베이스에는 Cassandra, HBase
그래프(Graph) 데이터베이스
대표적인 그래프 데이터베이스에는 Neo4J, InfiniteGraph
- 장점
- 대용량 데이터 처리를 하는데 효율적임.
- 읽기 작업보다 쓰기 작업이 더 빠르고 관계형 데이터베이스에 비해 쓰기와 읽기 성능이 빠름.
- 데이터 모델링이 유연함.
- 뛰어난 확장성으로 검색에 유리함.
- 최적화된 키 값 저장 기법을 사용하여 응답속도나 처리효율 등에서 성능이 뛰어남.
- 복잡한 데이터 구조를 표현할 수 있음.
- 단점
- 쿼리 처리시 데이터를 파싱 후 연산을 해야해서 큰 크기의 document를 다룰 때는 성능이 저하됨.
'코딩 교육 TIL' 카테고리의 다른 글
| 2024-03-20 AI 코딩 TIL (0) | 2024.03.20 |
|---|---|
| 2024-03-19 AI 코딩 TIL (0) | 2024.03.19 |
| 2024 -03-15 AI 코딩 TIL (4) | 2024.03.15 |
| 2024-03-14 AI 코딩 TIL (5) | 2024.03.14 |
| 2024-03-13 AI 코딩 TIL (0) | 2024.03.13 |