
어제에 이어 CS강의를 진행해 보도록 하겠습니다!
1. DBMS 정리
1-1. DBMS 개요
DBMS란 Database Management system의 준말로 모든사용자가 데이터를 모으고 사용 할 수 있습니다.
1-2. DBMS 용어

튜플(Tuple)
- 테이블에서 행을 의미합니다.
- 같은 말로는 레코드(Record) 혹은 로우(Row)라고도 부릅니다.
- 튜플은 릴레이션에서 중복되는 값을 가질 수 없습니다. 튜플의 수는 카디날리티(Cardinality) 라고 합니다.
어트리뷰트(Attribute)
- 테이블에서 열을 의미합니다.
- 같은 말로 칼럼(Columm)이라고도 부릅니다.
- 어트리뷰트(Attribute)의 수를 의미하는 단어는 **디그리(Degree)**라고 합니다. (Degree : 정도 → 도가 지나치다.)
릴레이션(Relation=Table)
- 관계형 데이터베이스에서 정보를 구분하여 저장하는 기본 단위입니다.
- ex. 유저 정보 > 유저 테이블, 게시글 정보 > 게시글 테이블 등…
키(Key)
- 테이블에서 행의 식별자로 이용되는 테이블의 열을 의미합니다. (ex. 유저 ID, 게시글 ID)
- 식별자(Identifier)
- 여러 개의 집합(인스턴스)체를 담고 있는 하나의 테이블에서 각각을 구분할 수 있는 논리적인 이름, 개념이며 이 구분자를 식별자(Identifier)라고 한다.
- 키는 주키와 외래키로 나뉘며 하나의 테이블에서 주키는 1개 또는 1쌍으로만 구성되고, 외래키는 여러 개로 구성될 수 있습니다.
- 주키(PK) : 현재 테이블에서 행을 식별하는 식별자
- 외래키(FK) : 현재 테이블과 연관되어 있는 외부 테이블과 연관된 행을 식별하는 식별자 (조인할 때 써서 조인키라고도 함)
도메인(Domain)
- 도메인은 하나의 어트리뷰트가 취할 수 있는 같은 타입의 원자값들 집합이다. 예를 들어 성별 어트리뷰트의 도메인은 남과 여의 데이터의 값만 가능하다. 나이 어트리뷰트의 도메인은 숫자의 값만 입력할 수 있다. 그 외의 값은 입력될 수 없다.
2. DBMS 기능
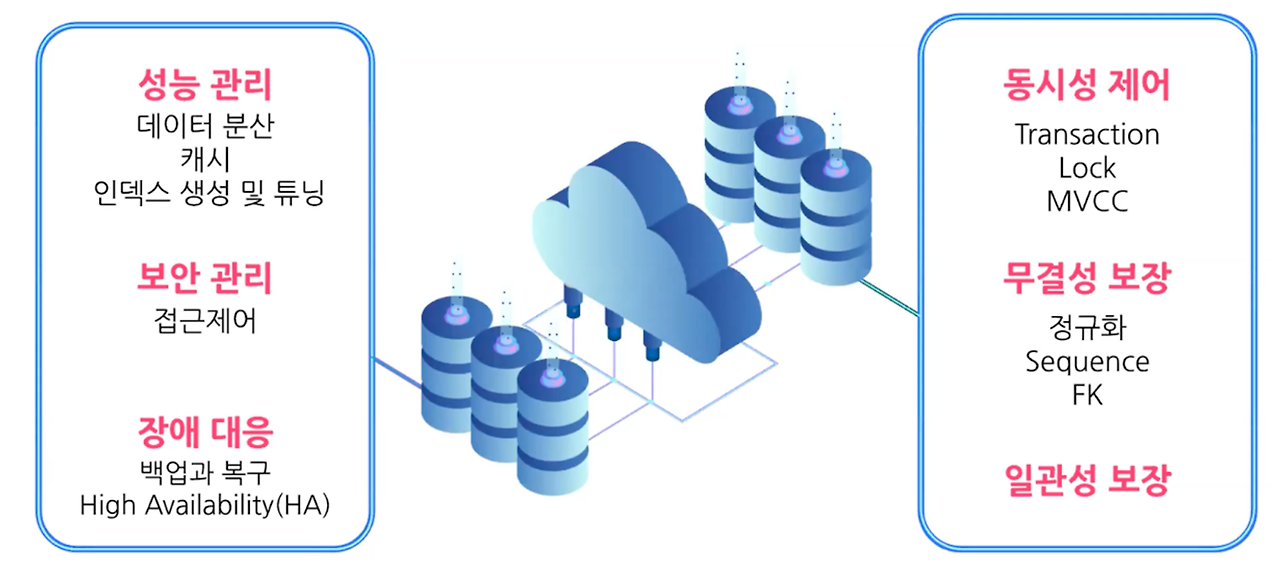
데이터를 안전하고 한 번에 관리할 수 있게 해주는 기능이라고 보면 된다.
Transaction(트랜잭션)
💁 트랜잭션 이란?
- DBMS의 요구사항을 충족시킬 핵심 기능입니다.
- 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위를 말합니다.
- ex. 회원가입 절차 = 가입 트랜잭션, 결제 절차 = 결제 트랜잭션
- 트랜잭션은 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위로 사용됩니다.
- ex. 회원가입, 결재는 작업 단위로 병행(따로) 처리됩니다.
- ex. 회원가입 처리중 잘못된 항목이 존재하여 가입불가시 가입취소(회복)가 됩니다.
- ex. 결재 처리중 잔액부족 등으로 결재가 불가능할경우 결재취소(회복)가 됩니다.
- 사용자가 시스템에 대한 요구 시 시스템이 응답하기 위한 상태 변환과정의 작업 단위로 사용됩니다.
- ex. 회원가입 요구시 가입완료 응답을 하기까지의 작업단위 = 가입 트랜잭션
- ex. 결재 요구시 결재완료 응답을 하기까지의 작업단위 = 결재 트랙잭션
트랜잭션의 특성
- 데이터의 무결성을 보장하기 위하여 DBMS의 트랜잭션이 가져야 할 특성
- 원자성(Atomicity) : 끝까지 가거나 끝가지 가지 못하면 데이터가 원상태로 돌아와야 한다.
- 일관성(Consistency) : 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.
- 독립성(Isolation) : 둘 이상의 트랜잭션이 동시에 실행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없다.
- 영속성, 지속성(Durability) : 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장이 나더라도 영구적으로 반영되어야 한다.
3. RDB(관계형 데이터베이스) = SQL DB
연관관계 (1:1, 1:N, N:M)

- 일대일 = 나 : 내 핸드폰 = 유저 : 프로필
- 일대다 = 나 : 담임 선생님 = 유저 : 게시글
- 다대다 = 나 : 동아리 = 게시글 : 해시태그게시글

- SQL 언어 종류
- DDL(Data Definition Language) : 데이터 정의어, 관계형 데이터베이스의 구조를 정의하는 언어이다. CREATE, ALTER, DROP, RENAME 문이 있다.
- DML(Data Manipulation Language) : 데이터 저작어, 테이블에서 데이터를 입력, 수정, 삭제, 조회한다. INSERT, UPDATE, DELETE, SELECT 문이 있다.
- DCL(Data Control Language) : 데이터 제어어, 데이터베이스 사용자에게 권한을 부여하거나 회수한다. GRANT, REVOKE, TRUNCATE 문이 있다.
- TCL(Transaction Control Language) : 트랜잭션을 제어하는 명령어이다. COMMIT, ROLLBACK, SAVEPOINT 문이 있다.
4. NoSQL
- NoSQL이라고도 부르며, Not Only SQL(SQL 뿐만이 아닌.이라는 뜻)의 줄임말이라고 합니다.
- NoSQL은 대부분 분산 환경에서의 데이터 처리를 더욱 빠르게 하기 위해 개발되었습니다.
자료의 저장과 표현
비트와 바이트
이진수 체계
이진수 체계는 0과 1 두 가지 숫자만을 사용하여 수를 나타내는 수의 체계입니다.
// 이진수 1010 를 10진수로 표현
1 * 2^3 + 0 * 2^2 + 1 * 2^1 + 0 * 2^0
= 8 + 0 + 2 + 0
= 10비트의 개념 (한 칸🔲)
비트는 컴퓨터에서 정보를 표현하는 가장 기본적인 단위입니다. 비트는 "binary digit"의 줄임말로, 이진수 체계에서 0과 1 두 가지 값을 가질 수 있는 최소한의 단위입니다.

- 비트로 표현한 데이터 예시
- 숫자: 8비트로 표현되는 부호 없는 정수를 생각해봅시다. 예를 들어, 8비트로 표현되는 숫자 42는 이진수로 00101010입니다. 여기서 각 비트는 0 또는 1 값을 나타냅니다.
- 문자: 문자는 컴퓨터에서 비트로 표현되어 텍스트로 저장됩니다. ASCII 인코딩을 사용하여 각 문자에 대해 8비트가 할당됩니다. 예를 들어, 문자 'A'는 ASCII 코드에서 65에 해당하며, 이는 이진수로 01000001로 표현됩니다.
- 색상: 컴퓨터 그래픽에서 색상은 비트로 표현됩니다. 예를 들어, 24비트 색상은 각각 빨강, 초록, 파랑 성분을 8비트씩 할당하여 표현합니다. 이진수로 표현된 색상 값은 각 성분에 대한 밝기나 강도를 나타냅니다.
- 파일: 파일은 컴퓨터에서 이진 데이터로 저장됩니다. 예를 들어, 이미지 파일은 픽셀 데이터로 구성되며, 각 픽셀은 색상 정보를 나타내는 비트로 표현됩니다.
바이트의 개념 (한 줄〰️)
바이트는 여러 개의 비트를 모아놓은 형태로, 보통 8개의 비트로 이루어져 있습니다.
- 바이트로 표현한 데이터 예시
- ASCII 문자열: ASCII 인코딩을 사용하여 문자열을 바이트로 표현할 수 있습니다. 예를 들어, "Hello"라는 문자열은 각 문자를 ASCII 코드에 맞게 바이트로 표현하면 다음과 같습니다:
- 'H': 72 (01001000)
- 'e': 101 (01100101)
- 'l': 108 (01101100)
- 'l': 108 (01101100)
- 'o': 111 (01101111)
- 이미지 파일: 이미지 파일은 픽셀 데이터로 구성되며, 각 픽셀의 색상 정보를 바이트로 표현합니다. 예를 들어, 24비트 컬러 이미지에서 각 픽셀은 빨강(R), 초록(G), 파랑(B)의 성분을 8비트씩 가집니다. 이진수로 표현된 색상 값은 픽셀마다 다양한 바이트로 구성됩니다.
- 음악 파일: 음악 파일은 소리의 파형 데이터로 구성되며, 일반적으로 디지털 오디오 형식을 사용하여 바이트로 표현됩니다. 각 샘플은 일정한 시간 간격으로 샘플링되고, 이러한 샘플링 데이터는 바이트로 표현됩니다.
- 실행 파일: 컴퓨터 프로그램은 실행 파일로 저장되고, 이 파일은 기계어로 표현된 바이너리 코드로 구성됩니다. 각 명령어와 데이터는 바이트로 표현되어 컴퓨터의 프로세서가 이를 이해하고 실행할 수 있습니다.
- ASCII 문자열: ASCII 인코딩을 사용하여 문자열을 바이트로 표현할 수 있습니다. 예를 들어, "Hello"라는 문자열은 각 문자를 ASCII 코드에 맞게 바이트로 표현하면 다음과 같습니다:
자료의 표현 형식
텍스트 자료의 표현
ASCII
- 가장 일반적으로 사용되는 문자 인코딩 중 하나는 ASCII (American Standard Code for Information Interchange)입니다.
- ASCII는 7비트로 구성되며, 각각의 비트 조합은 128개의 고유한 문자를 나타냅니다.
- ASCII 코드는 영어 알파벳, 숫자, 특수 문자 등을 포함합니다.
❓ 왜 ASCII는 1바이트(8비트)를 모두 사용하지 않고 7비트만 사용하였을까요?
7비트로 표현된 ASCII 코드는 2^7 = 128개의 고유한 값을 나타낼 수 있습니다. 이는 영어 알파벳, 숫자, 특수 문자 등을 포함한 기본적인 문자 집합을 표현하기에 충분합니다. 초기 컴퓨터 시스템에서는 주로 영문 텍스트를 다루기 때문에 7비트로 구성된 ASCII 코드가 널리 사용되었습니다.
7비트 ASCII는 0부터 127까지의 값을 사용하여 문자를 나타내는데, 예를 들어 'A'는 65, 'a'는 97로 표현됩니다. 나머지 128부터 255까지의 값은 사용되지 않거나, 다른 문자 인코딩 체계에 따라 확장 문자나 특수 문자로 사용될 수 있습니다.
유니코드 와 UTF-8
- 유니코드(Unicode):
- 유니코드는 전 세계의 모든 문자를 고유한 코드 포인트로 나타내는 국제 표준입니다.
- 유니코드는 "U+"로 시작하며, 각 문자는 16진수 값으로 표현된 코드 포인트를 나타냅니다.
- 각 문자에는 유니코드 코드 포인트라고 불리는 고유한 식별자가 할당됩니다. 이 코드 포인트는 16진수로 표현되며, 예를 들어 "A"는 U+0041과 같이 표현됩니다.
- UTF-8(Unicode Transformation Format-8):
- UTF-8은 유니코드를 컴퓨터에서 저장하고 전송하기 위한 가변 길이 문자 인코딩 방식입니다.
- UTF-8은 ASCII 문자에 대해서는 7비트로 표현하며, 다른 유니코드 문자는 8비트 이상으로 확장하여 표현합니다. 이를 통해 유니코드 문자를 효율적으로 저장하고 전송할 수 있습니다.
- UTF-8은 가변 길이 인코딩이기 때문에 유니코드 코드 포인트를 다양한 크기의 바이트 시퀀스로 변환합니다. ASCII 문자는 1바이트로 표현되며, 추가적인 문자는 2바이트부터 최대 4바이트까지 사용될 수 있습니다.
❓ 가변길이를 어떻게 구분해서 저장하고 읽어올까요?
- 유니코드에 먼저 등록된 영어와 숫자같은 문자는 1byte , 그뒤에 등록된 문자는 4byte와 같이 차별적 혹은 가변적으로 할당하는 방법을 택했습니다.
- 유니코드별 Byte 할당은 아래와 같습니다.

- 이제, byte 별로 가변길이 구분짓기 위해 첫바이트에 표식을 추가해줍니다.
- 1byte는 0으로 시작,
- 2byte는 110으로 시작하고,
- 3byte는 1110으로 시작,
- 4byte는 11110으로 시작,
- 나머지 byte는 10으로 시작합니다.

위의 예시를 보면, 곰은 U+ACF0이므로, 표상 3바이트 범위에 속한다. 3바이트 작성법은 위에 표에도 잘 나와있듯이, 1110 xxxx/10 xxxxxx/10 xxxxxx로 그대로 받아 적으면 된다.
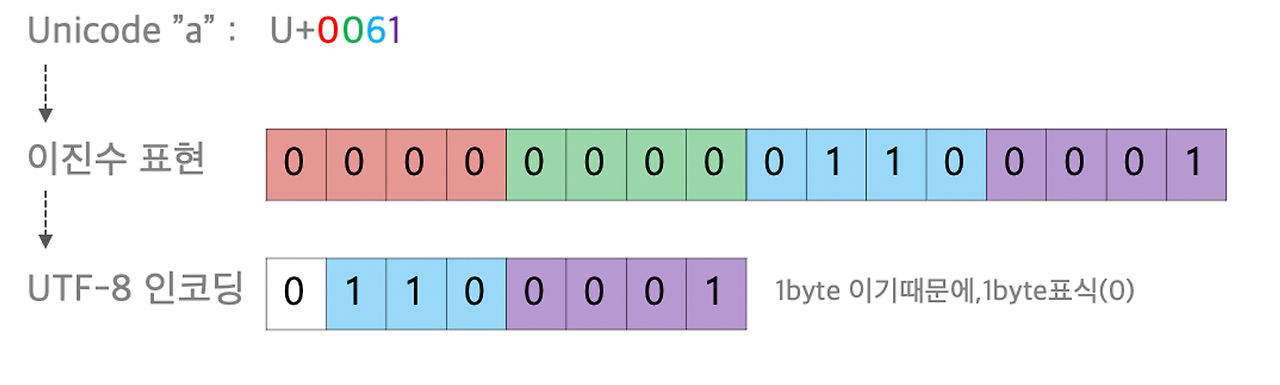
이 경우엔, "a"는 U+0061이므로, 1바이트 범위에 속하며, 1바이트의 표시형식을 참고하여 다음과 같이 인코딩 된다.
숫자 자료의 표현
- 부호 없는 정수:
- 이진수를 사용하여 양수만을 표현합니다.
- 예를 들어, 8비트로 표현된 부호 없는 정수에서 숫자 42는 이진수로 00101010으로 표현됩니다.
- 부호 있는 정수:
- 부호 있는 정수는 양수와 음수를 모두 표현할 수 있습니다.
- 일반적으로 2의 보수 (two's complement) 표현 방식을 사용합니다.
- 양수는 부호 비트가 0으로 표현되고, 음수는 부호 비트가 1로 표현됩니다.
- 실수:
- 실수는 소수점을 가지는 숫자를 표현합니다.
- 부동 소수점은 정밀도와 범위를 조절할 수 있으며, 대부분 IEEE 754 표준을 따릅니다.
❓ 2의 보수?
- 42의 이진수 표현:
- 42는 이진수로 00101010로 표현됩니다.
- 1의 보수:
- 2의 보수 변환을 위해 42의 이진수에 대해 1의 보수를 취합니다. 1의 보수는 0을 1로, 1을 0으로 반전시키는 작업입니다.
- 42의 1의 보수는 11010101입니다.
- 00101010를 반전한것
- 2의 보수:
- 1의 보수를 취한 결과에 1을 더함으로써 2의 보수를 얻을 수 있습니다.
- 11010101에 1을 더하면 11010110이 됩니다.
- 이는 -42를 음수로 표현한 2의 보수 표현입니다.
따라서, 42를 2의 보수로 변환하면 -42로 표현되는 것을 확인할 수 있습니다. 이러한 2의 보수 방식은 부호 있는 정수 표현에서 음수 값을 표현하는 데에 주로 사용됩니다.
자료구조의 동작과 활용
자료구조
Array (배열)
[ 배열의 특징 ]
- 순서가 있습니다. (메모리 순서대로)
- 연속된 공간을 '미리' 정해서 사용해야 합니다. (확정된 메모리 공간을 할당받아 써야 하므로)
- N번째 데이터에 접근하기 위해 복잡한 과정 필요 없이 그냥 덧셈과 곱셈 한 번이면 가능합니다. (n번째 데이터 접근 : 시작 주소 + (n-1) * 해당 자료형 크기)
- Create : 이미 new int [5];로 만들어져 있는 데이터인데 새로운 6번째 데이터를 새로 배열에 넣으려고 한다. 방법은 새로운 연속된 공간을 다시 할당받고 기존에 있던 데이터를 모두 새로운 곳으로 옮기는 방법입니다.
int[] arr = new int[5];
arr[0] = 1;
...// 무언가 넣음int[] tmp = new int[6];
for (int i = 0; i < arr.length; i++) {
tmp[i] = arr[i];
}
arr = tmp;- Read : 몇 번째 데이터라도 덧셈과 곱셈 한 번씩이면 접근할 수 있으므로 매우 빠르게 접근할 수 있습니다.
- Update : Read와 마찬가지로 매우 쉽게 접근해서 수정 가능합니다.
- Delete : Create처럼 어렵다. int [] arr = new int [5];에서 arr [3]을 제거하려고 할 때, Create의 예시처럼 new int [4]; 를 만든 후 복사해 넣어야 합니다. 혹은 공간 자체는 안 줄여도 된다고 해도 arr [3] 이후의 모든 값을 한 칸씩 앞으로 당겨줘야 합니다. (예외로 배열의 크기를 사용하는 데이터의 개수와 관계없이 유지해도 되고 마지막 데이터를 삭제하는 경우라면 한방에 가능합니다.)
💡 배열의 시간복잡도
- 데이터 읽기, 수정 : O(1)
- 데이터 추가, 삭제 : O(N)
- 예외 : 배열에 빈 공간이 존재하는걸 허용하며 짜는 경우라면 마지막 데이터의 추가, 삭제는 O(1)
LinkedList (리스트)
- 배열은 메모리 자체에 순서대로 들어가 있으므로 다음 데이터는 물론이고, n번째 데이터도 쉽게 알 수 있다.
- 하지만 리스트는 현재 그림상으로는 리스트에서 첫 번째 데이터인 '12'의 위치는 알 수 있지만 n번째 데이터는커녕 바로 다음 데이터도 어디에 있는지 알 수 없다.
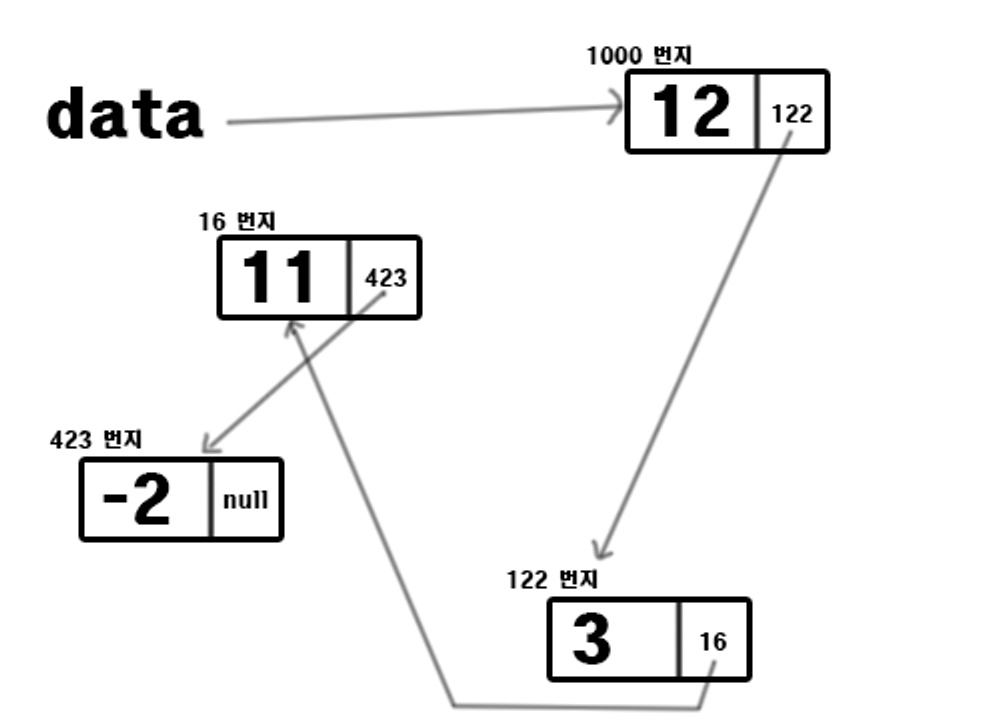
💡 리스트. Create 시간복잡도
- 리스트의 중간에 데이터를 넣을 경우 : O(N)
- 맨 앞이나 맨 뒤에 넣을 경우 : O(1) - 일반적으로 이 경우가 많음
💡 리스트. Read/Update 시간복잡도
- 맨앞이나 맨 뒤의 데이터를 확인하거나 바꿀 경우 : O(1)
- 중간의 데이터를 확인하거나 바꿀 경우 : O(N) - 일반적으로 이 경우가 많음
💡 리스트. Delete 시간복잡도
- 중간의 데이터를 삭제할 경우 : O(N)
- 맨앞이나 맨 뒤에 데이터를 확인하거나 바꿀 경우 : O(1) - 일반적으로 이 경우가 많음
❓ 배열은 언제 쓰고 리스트는 언제 쓸까?
결국 시간복잡도와 상황에 맞게 적절하게 사용하면 됩니다.
- 리스트
- 일반적으로 데이터의 추가, 삭제가 많은 경우 리스트를 사용하는 것이 효율이 좋습니다.
- 배열
- 데이터가 자주 추가, 삭제되지 않고, 읽고 수정하는 경우가 많을 때 배열을 사용하는 것이 효율이 좋습니다.
ArrayList (벡터)
- 기본 동작 원리 및 CRUD에 따른 효율성은 모두 배열과 동일합니다.
- 이걸 이해하는 게 매우 중요한 게, 보통 자료구조에 대해 잘 모르고, 자바 자체도 초보인 사람들은 리스트를 처음 사용할 때 ArrayList와 LinkedList 둘 중 대충 아무것이나 쓰고 한번 써봤으니깐 그걸로 앞으로 계속 써버립니다.
- 당연히 LinkedList와 ArrayList의 CRUD 효율성은 매우 다르므로 아무꺼나 쓰면 매우 비효율적인 코드가 돼버립니다. 자바에서 ArrayList는 배열을 썼을 때 효율적으로 동 잘할 로직을 수행하려고 하는데, 배열의 크기를 모를 때, 혹은 배열로 구현하기 귀찮을 때 어차피 메모리 크기 여유롭면 대충 넣기 좋으니까 사용하는 것입니다.
- 심지어 배열로 해도 그냥 미리 넉넉하게 만들거나, 다 차면 미리 한 2배 정도로 늘려서 새로 만들어버리면 ArrayList와 동일하게 사용 가능합니다.
Queue, Stack (큐, 스택+덱)
큐 (Queue)
큐는 FIFO(First in First out; 선입 선출)의 특징을 가지는 자료구조이다. 먼저 들어간 데이터가 먼저 나옵니다.
- 모든 함수의 시간복잡도는 O(1)이어야 한다.
❓ 언어별 Queue
- 자바의 경우 'Queue<Integer> q = new LinkedList<>();' 와 같이 선언해서 사용 가능합니다.
- 파이썬은 따로 큐를 제공하지 않는다. 애초에 파이썬은 배열도 없는 판국에 뭐..(심지어 리스트는 linked list가 아님) 파이썬에서 list는일반적으로 Vector(ArrayList)의 형식으로 동작하므로 dequeue에서 시간복잡도가 너무 높아 비효율적이다. 파이썬은 큐도 이후 설명할 deque(덱)를 사용해야 합니다.
- **C++**은 STL에 만들어놨습니다.
- C는 일단 LinkedList부터 기본적으로 제공되지 않으므로 전부 직접 짜야합니다.
❓ Queue는 어떨 때 쓸까?
현업에서 쓸만한 예시로는 대표적으로 스케쥴링에 쓰인다. 먼저 들어온 작업을 먼저 처리하도록 하는 것입니다.
스택 (Stack)
스택은 LIFO(Last in First out; 후입 선출)의 특징을 가지는 자료구조이다. 나중에 들어간 데이터가 먼저 나옵니다.
- 마찬가지로 모든 함수의 시간복잡도는 O(1)이어야 합니다.
덱 (Deque = Double-ended Queue)
- Double-ended Queue라는 의미로, 양쪽으로 넣고 뺄 수 있는 큐입니다.
- 당연히 양쪽으로 넣고 뺄 수 있는 스택으로도 쓸 수 있고, 한쪽은 스택 한쪽은 큐로 써도 됩니다.
- 좀 더 유연한 스택, 큐입니다.
- 하지만 리스트와 다르게 중간의 데이터를 건드릴 수 없고, 양 끝단만 건드릴 수 있습니다.
Hash Table (맵)
- key: value로 저장하는 데이터 구조
- 키를 통해 바로 데이터를 받아올 수 있어 속도가 획기적으로 빨라짐
- 해쉬 : 임의 값을 고정 길이로 변환하는 것
- 해쉬 테이블 : 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 해쉬 함수 : 키에 대해 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
- 해쉬 값 / 해쉬 주소 : 키를 해싱 함수로 연산해서 해쉬 값을 알아내고 이를 기반으로 해뷔 테이블에서 해당 키에 대한 데이터 위치를 일관성 있게 찾을 수 있음
- 슬롯 : 한 개의 데이터를 저장할 수 있는 공간
- 저장할 데이터에 대해 키를 추출할 수 있는 별도 함수도 존재할 수 있음
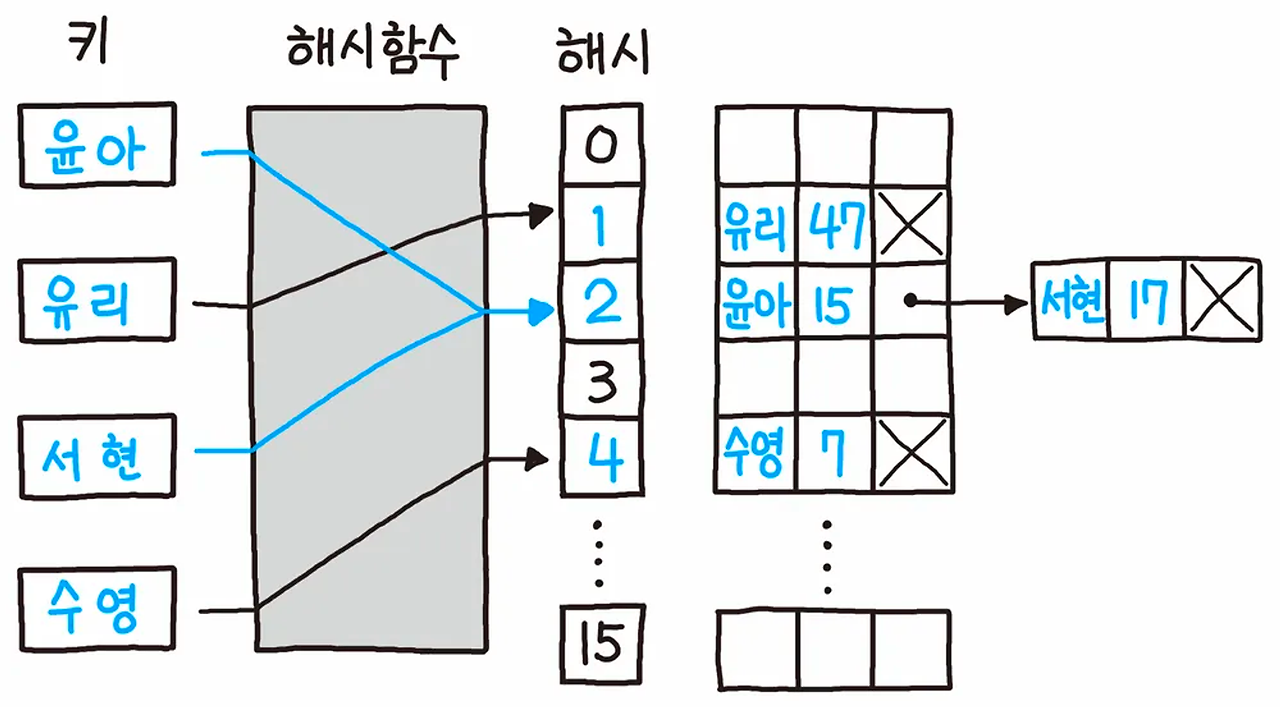
해시(Hash)
데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
해시 함수를 구현하여 데이터 값을 해시 값으로 매핑합니다.
Lee → 해싱함수 → 5
Kim → 해싱함수 → 3
Park → 해싱함수 → 2
...
Chun → 해싱함수 → 5 // Lee와 해싱값 충돌
결국 데이터가 많아지면, 다른 데이터가 같은 해시 값으로 충돌 나는 현상이 발생함 'collision' 현상
해시 테이블을 쓰는 이유는?
- 언제나 동일한 해시값 리턴, index를 알면 빠른 데이터 검색이 가능해짐
- 해시테이블의 시간복잡도 O(1) - (이진탐색트리는 O(logN))
💡 **collision(**충돌)’ 문제 해결
- 체이닝 : 연결리스트로 노드를 계속 추가해나가는 방식 (제한 없이 계속 연결 가능, but 메모리 문제)
- Open Addressing : 해시 함수로 얻은 주소가 아닌 다른 주소에 데이터를 저장할 수 있도록 허용 (해당 키 값에 저장되어있으면 다음 주소에 저장)
- 선형 탐사 : 정해진 고정 폭으로 옮겨 해시값의 중복을 피함
- 제곱 탐사 : 정해진 고정 폭을 제곱수로 옮겨 해시값의 중복을 피함
Set (셋)
Set의 특징
- 데이터를 비순차적(unordered)으로 저장할 수 있는 순열 자료구조 (collection).
- 집합의 개념과 같다고 생각하면 된다.(집합 역시 {1, 9, 6, 4}처럼 중복과 순서가 없다.)
- 삽입(insertion) 순서대로 저장되지 않는다. 즉 특정한 순서를 기대할 수 없는 자료구조.
- 수정 가능합니다.(mutable)
- 동일한 값을 여러 번 삽입 불가능합니다.
- 동일한 값이 여러번 삽입되면 하나의 값만 저장됩니다.
- Fast Lookup이 필요할 때 주로 쓰입니다.
- Set이라는 인터페이스를 통해 자바에서는 3가지의 Set이 있다. 일반적으로 HashSet, TreeSet, LinkedHashSet 순으로 빠르다.
- Hash 알고리즘을 이용한 HashSet
- 이진 탐색 트리를 사용하여 오름차순 정렬까지 해주는 TreeSet
- Set에 순서를 부여해 주는 LinkedHashSet
Set의 구조
- Array와 달리 set은 요소들을 순차적으로 저장하지 않습니다.
- Set에서 요소들이 저장될 때 순서는 다음과 같습니다.
- 저장할 요소의 값의 hash 값을 구한다.
- 해쉬값에 해당하는 공간(bucket)에 값을 저장합니다.
- 이렇게 set는 저장하고자 하는 값의 해쉬값에 해당하는 bucket에 값을 저장하기 때문에 순서가 없다. 순서가 없기 때문에 indexing도 없습니다.
- 그리고 해쉬값 기반의 bucket에 저장하기 때문에 중복된 값을 저장할 수 없는 것입니다.
- 해쉬값을 기반으로 저장하기 때문에 look up 이 굉장히 빠릅니다.
- Look up: 특정 값을 포함하고 있는지를 확인하는 것
- O(1): Set의 총길이와 상관없이 단순히 해쉬값 계산 후 해당 bucket을 확인하면 됩니다.
HashSet
- 내부적으로 HashMap을 사용하여 값을 저장합니다.
- 값의 중복을 허용하지 않습니다.
- 값이 저장된 순서를 보장하지 않습니다.
- null을 허용합니다.
그렇다면 언제 Set을 쓸까요?
- 순서보장이 필요 없고 중복은 없어야 하는 “이벤트 응모자 목록”과 같은 자료를 저장할 때 사용할 수 있습니다.
- 해쉬값 기반이기 때문에 조회속도가 빠른 장점을 사용해 실시간 처리에도 사용할 수 있습니다.
OSI 7 계층
네트워크
우리가 흔히 아는 인터넷 연결에 대해서
통신 장비, 통신 역할, 통신 규칙이 필요하다.
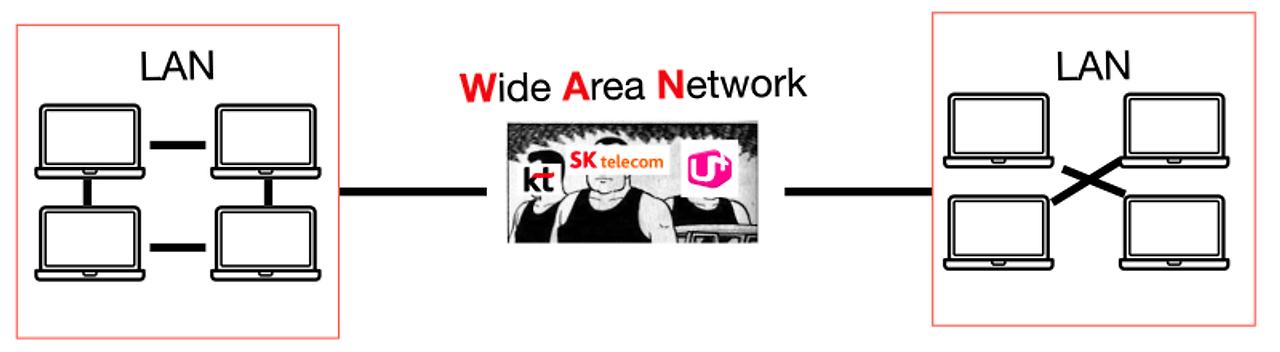
✋ LAN vs WAN
- LAN (Local Area Network)
- 사무실이나 빌딩처럼 비교적 좁은 범위의 네트워크를 말한다.
- WAN (Wide Area Network)
- 서로 떨어져 있는 LAN 사이를 전용선 등으로 연결한 광역 네트워크를 말한다.
- LAN을 통해 건물의 네트워크에 접속하거나 자원을 공유할 수 있다.
- WIFI 공유기를 통해 노트북이나 핸드폰으로 인터넷에 연결하는것도 LAN
- WIFI 공유기를 통해 컴퓨터에서 프린터에 연결하는것도 LAN
💁♂️ 달달한 허니팁 한입!
- 집에있는 WIFI 공유기에 맨 왼쪽 포트가 WAN 포트이고 나머지 포트가 LAN 포트라는 사실!
- WAN을 통해 멀리 떨어져 있는 LAN 사이를 연결할 수 있다.
- WAN 전용선으로 건물과 통신사 중계기(ISP)를 연결하는 것도 WAN
- WAN 케이블로 네트워크 시스템(SDN)을 통해 미국의 네트워크에 연결하는것도 WAN
💁♂️ 달달한 허니팁 두입!
- 우리나라는 1982년 5월에 미국에 이어 세계에서 두번째로 인터넷 연결을 한 나라 라는 사실!
튜터님 강의
우리는 AI를 만들수 없다 ㅎㅎ 그러니 이미 만들어진 것들을 이용하자
그러므로 휴먼과 AI간에 인터페이스를 만들자
서버에 대해서
먼저 클라이언트란?
인터넷 창 처럼 우리가 보이는 화면을 말한다.
여기서 입력한 것들이 서버로 가서 데이터를 조회한다.
간단하게 설명하면 서빙하는 웨이터 같은 느낌이다.
휴먼이 리퀘스트를 보내면 서버에서 데이터를 찾아서 리스폰 하는 개념
임대서버 AWS IPV4(XXX.XXX.XXX.XXX)빌리기
SSH키 .PEM키 .PPK키 등으로 전용 키가 있어야 접속 가능
그 다음으로 도메인을 구매해서 내 주소 명을 GOOGLE.COM같이 바꾸어 줄 수 있다.
'코딩 교육 TIL' 카테고리의 다른 글
| 2024-03-21 AI 코딩 TIL (0) | 2024.03.21 |
|---|---|
| 2024-03-20 AI 코딩 TIL (0) | 2024.03.20 |
| 2024-03-18 AI 코딩 TIL (3) | 2024.03.18 |
| 2024 -03-15 AI 코딩 TIL (4) | 2024.03.15 |
| 2024-03-14 AI 코딩 TIL (5) | 2024.03.14 |