
모의 면접 질문 답변을 만들어보자.
자료구조를 알아야 하는 이유에 대해 서술하시오
데이터를 효율적으로 저장하기 위해서 최적에 저장공간을 할당할 수 있는 자료구조를 선택해야 하며 각 자료구조의 데이터의 삽입과 호출의 특성을 이용해서 유용하게 데이터를 사용할 수 있기 때문에 자료구조를 잘 알고 있어야 합니다.
예를 들어 데이터를 사용할 때 8byte만 사용해도 될 데이터를 16byte 32byte에 저장을 하게 된다면 하나일 때에는 큰 차이가 나지 않겠지만 점점 많은 데이터를 받게 되면서 낭비하는 데이터 때문에 새로운 데이터를 받을 수 없게 될 것이고 너무 작은 자료구조를 사용한다면 갑자기 커져버린 데이터를 받아들일 수가 없게 되어버려서 오류가 날 수 있는 상황이 있습니다. 그렇기 때문에 알맞은 상황에 알맞은 데이터를 이용할 수 있게 하기 위해서는 자료구조를 잘 알고 있어야 합니다.
자료구조에 대해서 간단하게 정의해 주세요.
자료구조는 데이터를 구조화하고 저장하기 위한 방법이나 원리를 나타냅니다. 자료구조의 방식으로는 선형 방식과 비선형 방식이 있으며 선형 방식에는 데이터 저장을 한 방향으로 저장을 해서 데이터와 데이터를 이어서 저장을 합니다. 이로 인해서 저장하고 접근하기에 유용한 방식이며 예시로는 리스트와 배열, 스택, 큐등이 있으며, 비선형 방식은 선형방식과 달리 데이터를 한 방향으로 저장하는 것이 아닌 하나의 데이터가 여러 가지의 데이터와 이어져있는 방식으로 되어 있으며 데이터의 복잡한 관계를 표현하거나 탐색하기에 유용한 자료구조 방식입니다. 예시로는 그래프, 트리, 해시 테이블이 있습니다.
OOP란?
OOP는 Object-Oriented Programming(객체 지향 프로그래밍)의 약어입니다.
우리가 코딩에 사용했던 것 중에 밀접한 방법으로는 클래스가 있습니다. 우리가 클래스에서 인스턴스를 만들면 각 인스턴스가 클래스 안에 매머드에 작동을 할 때 서로 간에 간섭을 주지 않는 것을 볼 수 있는데 이런 것이 OOP라고 할 수 있습니다. 이와 같은 방법을 이용해서 오는 이점으로는 코드를 재사용 및 상속을 받으므로 확장을 시킬 수 있다는 점에서 효율적으로 프로그래밍을 할 수 있습니다.
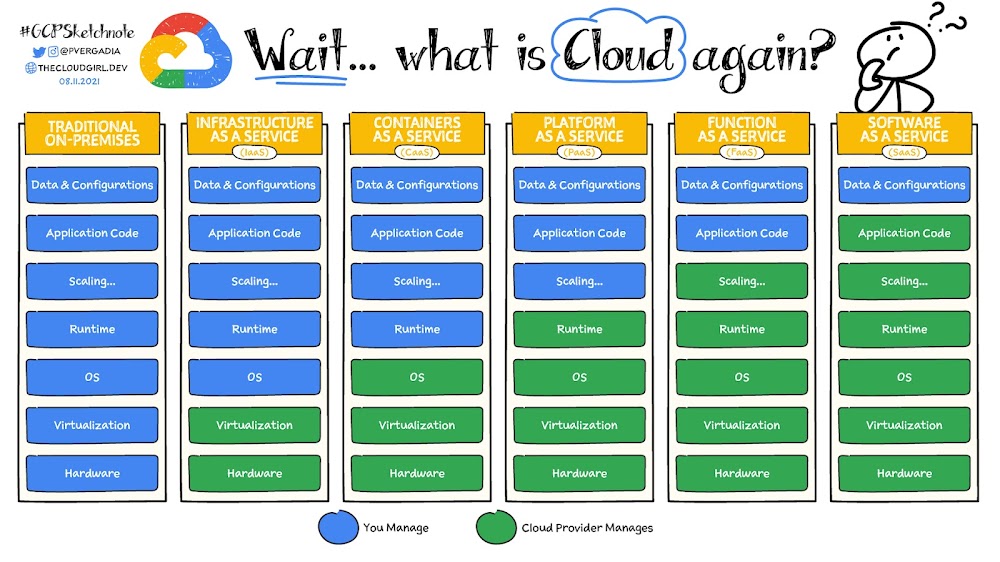
클라우드 서비스 모델에 대해 무엇이 있으며, 각각 설명하시오
클라우드 서비스 모델에는 주로 다음과 같은 6 가지 모델이 있으며 IaaS, CaaS, PaaS, FaaS, SaaS 각 모델의 차이점을 쉽게 설명을 하자면 클라우드에서 얼마나 관여를 하는지의 차이로 나누어 볼 수 있습니다. IaaS에서부터 SaaS로 갈수록 클라이언트보다 서버의 클라우드 서비스가 관리를 하는 비율이 점차 올라가며 클라우드 서비스를 이용하므로 관리를 할 종목이 작아지고 성능의 제약이 덜어진다는 장점이 있는 반면에 내가 직접 수정을 할 수 있는 범위가 줄어듬과 관리 비용이 올라간다는 단점이 있습니다.
IaaS 인프라스트럭처 서비스 : 이 모델에서는 가상화된 컴퓨팅 리소스(가상 머신, 스토리지, 네트워킹 등)를 인터넷을 통해 제공합니다. 사용자는 이를 통해 인프라를 구축하고 운영할 수 있으며, 가상 머신 인스턴스를 시작하고 종료하고, 스토리지에 데이터를 저장하고 검색할 수 있습니다. 대표적인 서비스로는 Amazon Web Services(AWS)의 EC2, Microsoft Azure의 Virtual Machines 등이 있습니다.
CaaS 컨테이너 서비스: CaaS는 개발자가 애플리케이션을 컨테이너로 패키징하고, 이를 관리하고 실행하는 환경을 제공합니다. 이 모델은 애플리케이션을 보다 쉽게 개발, 배포, 확장하고 관리할 수 있도록 도와줍니다.
PaaS 플랫폼 서비스 : 이 모델에서는 응용 프로그램을 개발, 테스트, 배포 및 관리하기 위한 플랫폼을 제공합니다.
개발자는 애플리케이션을 만들기 위한 소프트웨어 개발 도구, 런타임 환경, 데이터베이스, 웹 서버 등을 제공받습니다.
대표적인 서비스로는 Google App Engine, Heroku, Microsoft Azure의 App Service 등이 있습니다.
FaaS 함수 서비스 : 이 모델에서는 개발자가 코드(함수)를 업로드하고 클라우드 공급자가 코드를 실행할 때만 비용이 청구됩니다. 개발자는 서버 및 인프라를 관리할 필요 없이 개별적인 함수 단위로 작업을 실행할 수 있습니다.
대표적인 서비스로는 AWS Lambda, Azure Functions, Google Cloud Functions 등이 있습니다.
SaaS 소프트웨어 서비스 : 이 모델에서는 클라우드 공급자가 애플리케이션을 호스팅 하고 고객은 웹 브라우저를 통해 해당 애플리케이션을 사용합니다. 사용자는 애플리케이션을 설치하거나 유지 관리할 필요 없이 인터넷을 통해 액세스 할 수 있습니다. 대표적인 서비스로는 구글 드라이브, Microsoft 365, Salesforce 등이 있습니다. 요즘 사용하는 ChatGPT가 여기에 해당한다고 합니다.
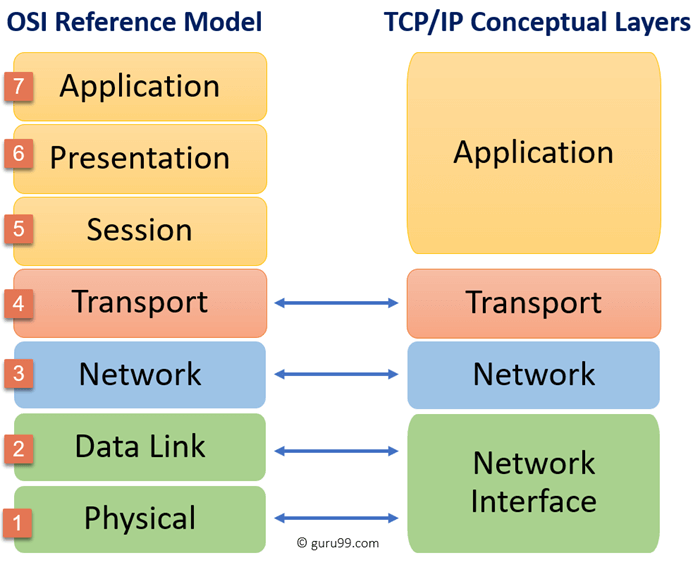
네트워크 OSI, TCP/IP 모델을 비교하시오
OSI 모델과 TCP/IP 모델은 모두 네트워크 통신을 설명하기 위한 추상적인 모델입니다. 그러나 OSI 모델은 7개의 계층으로 구성되어 있고, TCP/IP 모델은 4개의 계층으로 구성되어 있습니다. TCP/IP 모델은 OSI 모델을 단순화하고 현실적인 네트워크 프로토콜 스택을 제공하는 데 사용됩니다.
OSI는 ISO에서 개발한 통신 계층으로 유저가 보게 되는 클라이언트와 서버의 위치인 7 계층부터 데이터가 만들어져서 전송이 되는 1 계층으로 구성이 되어있으며 우리가 사용하는 컴퓨터가 데이터를 알맞은 서버에 보내기 위해서 거쳐지는 단계를 표시한 것이라고 보면 되며 7 계층을 조금 더 현실적으로 단순화해서 만들어진 것이 TCP/IP입니다.
TCP, UDP 차이를 말하시오
TCP (Transmission Control Protocol):
연결 지향적인 프로토콜로, 데이터 전송 전에 연결을 설정합니다.
데이터의 정확성과 순서를 보장하기 위해 신뢰성 있는 전송을 제공합니다.
흐름 제어와 혼잡 제어를 통해 네트워크 혼잡을 관리합니다.
데이터 전송 후에는 연결을 해제합니다.
상호 간에 확인이 필요하기 때문에 확인이 끝난 후 데이터를 전송을 하므로 신뢰성을 올라가나 그만큼 시간이 걸립니다.
이와 같은 방법을 사용하는 것이 보안이 필요한 부분이나 이메일등 개인적인 데이터를 받을 때 필요로 합니다.
UDP (User Datagram Protocol):
비연결 지향적인 프로토콜로, 데이터 전송 시 연결 설정 없이 바로 전송합니다.
신뢰성이 낮고, 데이터 전송 순서가 보장되지 않습니다.
헤더 오버헤드가 작고, 전송 속도가 빠르며, 실시간 응용 프로그램에서 사용됩니다.
데이터 전송 후에는 별도의 연결 해제 과정이 없습니다.
TCP와 반대로 확인이 없이 일방적인 데이터 전송으로 그만큼 시간이 단축이 된다는 장점이 있지만 데이터의 대한 신뢰도는 떨어질 수 있다는 단점이 있습니다.
이런 방식을 이용하는 곳은 빠른 속도가 요구되는 게임처럼 즉각 적인 반응이 필요로 하는 곳이나 동영상 스트리밍처럼 영상이 끊기지 않도록 빠르게 받아야 할 때 사용이 됩니다.
프로토콜이 무엇이며, 알고 있는 프로토콜 중 하나를 설명하시오
프로토콜은 컴퓨터 네트워크에서 통신하기 위한 규칙과 규약을 의미합니다. 다양한 프로토콜이 네트워크 통신에서 사용되며, 각각의 프로토콜은 특정한 목적이나 특성을 가지고 있습니다.
우리가 일반적으로 사용하는 인터넷 브라우저에 사용되는 통신프로토콜로 HTTP와 HTTPS가 있습니다.
HTTP(Hypertext Transfer Protocol): 월드 와이드 웹(World Wide Web)에서 사용되는 프로토콜로, 웹 서버와 클라이언트 간에 데이터를 주고받는 데 사용됩니다. HTML 문서, 이미지, 비디오, 오디오 등의 다양한 형태의 데이터를 전송할 수 있습니다.
HTTPS(Hypertext Transfer Protocol Secure): HTTP의 보안 버전으로, 데이터 전송 과정에서 암호화를 적용하여 보안성을 확보합니다. 주로 인터넷을 통한 민감한 정보 전송에 사용됩니다.
또한 위에서 질문했던 TCP나 UDP도 프로토콜에 해당합니다.
그래프의 인접 리스트와 인접 행렬의 차이점은 무엇인가요?
1. 인접 행렬 : 노드와 간선을 2차원의 방식으로 정의하여 한 번에 보기 좋은 형태
- 장점: 두 노드의 간선의 존재 여부를 바로 알 수 있음, 행렬로 되어 있기 때문에 데이터를 찾을 때 효율적으로 찾을 수 있습니다. 간선이 많을수록 리스트에 비해 유용하며, 서로 연결되어 있는 관계를 알기 쉽다.
- 단점: 행렬로 만들어야 하기에 노드 개수에 비래 하여 데이터 크기는 N^2의 수로 필요로 하기에 노드의 개수가 많을수록 불필요한 메모리 낭비가 일어남,
2. 인접 리스트 : 선형 방식의 데이터 저장으로 데이터를 효율적으로 저장이 가능하다.
- 장점: 연결된 것들만 기록하기에 노드의 수가 많아져도 데이터의 낭비를 줄일 수 있음 / 어떤 노드의 인접한 노드들을 바로 알 수 있음
- 단점: 두 노드가 연결되어 있는지 확인이 인접 행렬보다 느림, 노드 연결이 많아지면 한 번에 확인하기 안 쉬워진다.
시간 복잡도와 공간 복잡도의 차이는 무엇인가요?
시간 복잡도(Time Complexity)와 공간 복잡도(Space Complexity)는 알고리즘의 성능을 측정하는 두 가지 주요 지표입니다. 둘 다 Big O 표기법을 사용하여 나타내지만, 시간 복잡도는 알고리즘의 실행 시간에 대한 함수를, 공간 복잡도는 알고리즘이 실행되는 동안 필요한 메모리 공간의 양에 대한 함수를 나타냅니다.
재귀 함수(Recursive Function)가 무엇이며, 어떤 상황에서 사용하나요? 예시를 들어 설명해 주세요.
재귀 함수(Recursive Function)는 함수 내부에서 자기 자신을 호출하는 함수를 말합니다.
재귀함수를 호출할 때마다 스택구조의 스택프레임에 저장이 되며 재귀 케이스를 만나면 스택이 쌓이며 기본 케이스를 만나면 리턴 값을 가지고 스택프레임에 저장된 스택을 꺼내어서 값을 반영합니다.
재귀함수가 사용되는 상황으로는 수학적/수열 문제 해결, 트리 구조를 다루는 문제, 분할 정복 알고리즘등에서 사용이 가능하며 예시로는 일반적인 수학 공식의 팩토리얼 계산(n!), 피보나치 함수가 있으며 알고리즘으로 이진탐색을 사용할 때 DFS를 이용하는 방식에 재귀함수를 사용합니다.
데이터베이스와 SQL은 무엇인가요?
데이터베이스(Database)는 구조화된 데이터를 저장, 관리, 조작하는 데 사용되는 시스템입니다. 데이터들은 테이블 형식으로 구조화하여 저장이 되며 각 테이블은 레코드와 필드로 이루어져 있습니다. 데이터 베이스의 장점으로는 여러 사용자가 동시에 사용이 가능하다는 점이 있으며 데이터의 공유와 협업이 유용합니다. 이러한 데이터 베이스를 사용하기 위해서 SQL(Structured Query Language)은 데이터베이스와 상호 작용하기 위한 표준화된 프로그래밍 언어입니다. SQL은 데이터베이스의 구조를 나타내는 스키마, 데이터의 삽입, 수정, 삭제, 조회등의 작업을 진행할 수 있습니다. SQL은 대부분의 관계형 데이터베이스 관리 시스템(RDBMS){= MYSQL, ORACLE}에서 사용됩니다.
배열과 연결 리스트의 차이는 무엇인가요? 각각의 장단점은 무엇인가요?
- 배열(Array):
연속된 메모리 공간에 데이터를 저장합니다.
각 요소는 인덱스를 통해 직접적으로 접근할 수 있습니다. - 연결 리스트(Linked List):
각 요소는 자신의 데이터와 다음 요소를 가리키는 포인터로 이루어진 노드로 구성됩니다.
메모리에 연속된 공간에 저장되지 않고, 각 노드가 다음 노드를 가리키는 포인터를 통해 연결됩니다.
접근 속도
배열 : 특정 인덱스에 직접 접근할 수 있으므로, 해당 인덱스의 요소에 대한 접근이 빠릅니다. 시간 복잡도는 O(1)입니다.
연결 리스트: 특정 위치에 접근하려면 첫 번째 노드부터 시작하여 해당 위치까지 포인터를 따라가야 합니다. 이 때문에 접근 속도가 느릴 수 있습니다. 시간 복잡도는 최악의 경우 O(n)입니다.
메모리 사용량
배열 : 배열은 요소가 연속된 메모리에 저장되므로, 고정된 크기를 가지고 있습니다.
연결 리스트 : 연결 리스트는 각 노드가 개별적으로 메모리에 할당되므로, 동적으로 크기가 조절될 수 있습니다. 따라서 메모리 사용량이 유연하게 조절될 수 있습니다.
배열은 빠른 접근 속도를 가지지만 삽입 및 삭제 연산이 비효율적이고, 크기가 고정되어 있습니다. 반면에 연결 리스트는 삽입 및 삭제 연산이 효율적이지만 접근 속도가 느리고, 메모리 사용량이 유연하게 조절될 수 있습니다.
리스트에서 삽입 삭제 하는 방법을 자유롭게 알려주세요.
리스트의 각 요소는 자신의 데이터와 다음 요소를 가리키는 포인터로 이루어진 노드로 구성이 되어 있기 때문에 각 노드를 어디에 넣는가에 따라서 달라진다. 일단 기본적으로 맨 마지막에 데이터를 넣는다고 하면 가장 마지막에 저장된 노드에 새롭게 넣을 노드의 주소를 포인터로 저장을 하고 새로운 노드에 데이터를 넣어주는 것이고 만약에 중간에 데이터가 들어가는 경우에는 사이에 들어가게 될 데이터 앞부분의 노드에는 새로 들어가는 노드의 주소를 포인터로 새로운 노드에는 그 뒤에 있는 노드의 주소를 포인터로 넣어 주게 된다. 맨 앞은 동일한 방식으로 새로운 노드에 기존에 맨 앞에 있던 노드의 주소를 포인터로 넣어준다.
트리에 대해서 간단하게 정의해 주세요.
트리 구조는 트리의 뿌리에 해당하는 맨 상위에 있노드에서부터 1개 이상의 노드와 연결되어 뻗어나가는 구조의 방식이며 특정 노드에서 자신보다 상위에 있는 노드를 부모노드 자신보다 아래의 있는 노드를 자식노드로 칭한다. 트리의 특징은 계층적인 구조를 가지고 있다는 것이며 데이터 검색, 정렬, 삽입, 삭제에 효율적으로 수행할 수 있습니다.
추가적으로 루트는 하나만 존재합니다.
파이썬에서 기본 자료형 3가지 이상 간단하게 설명해 주세요
파이썬에는 아래와 같이 있습니다.
- 정수형 (int):
정수를 나타내는 자료형입니다. 양수, 음수, 0을 모두 표현할 수 있습니다.
예: x = 10, y = -5 - 실수형 (float):
부동 소수점 수를 나타내는 자료형입니다. 소수점 아래 숫자를 포함할 수 있습니다.
예: pi = 3.14, height = 1.75 - 문자열 (str):
문자들의 시퀀스를 나타내는 자료형입니다. 작은따옴표(')나 큰 따옴표(")로 감싸서 표현합니다.
예: name = 'Alice', message = "Hello, world!" - 부울형 (bool):
논리값인 참(True)과 거짓(False)을 나타내는 자료형입니다.
예: is_valid = True, is_finished = False - 리스트 (list):
여러 개의 값을 순서대로 저장하는 자료형입니다. 대괄호([])를 사용하여 표현하며, 값들은 쉼표(,)로 구분합니다.
예: numbers = [1, 2, 3, 4, 5], fruits = ['apple', 'banana', 'orange'] - 튜플 (tuple):
리스트와 유사하지만, 한 번 생성된 값은 변경할 수 없는(불변의) 자료형입니다. 괄호(())를 사용하여 표현하며, 값들은 쉼표(,)로 구분합니다.
예: point = (10, 20), colors = ('red', 'green', 'blue') - 집합 (set):
중복된 값을 허용하지 않고, 순서가 없는 자료형입니다. 중괄호({})를 사용하여 표현하며, 값들은 쉼표(,)로 구분합니다.
예: prime_numbers = {2, 3, 5, 7, 11}, vowels = {'a', 'e', 'i', 'o', 'u'} - 사전 (dictionary):
키-값 쌍으로 데이터를 저장하는 자료형입니다. 중괄호({})를 사용하여 표현하며, 각 키와 값은 콜론(:)으로 구분하고, 각 쌍은 쉼표(,)로 구분합니다.
예: person = {'name': 'Alice', 'age': 30, 'city': 'New York'}, scores = {'math': 90, 'english': 85, 'science': 95}
재귀 함수에 대해서 간단하게 정의해 주세요.
재귀 함수(Recursive Function)는 함수 내부에서 자기 자신을 호출하는 함수를 말합니다. 재귀 함수는 재귀 호출을 중단할 조건이 필요하며, 이를 base case라고 합니다. base case가 없으면 함수는 무한히 호출되며 스택 오버플로우(Stack Overflow)가 발생할 수 있습니다.
BFS는 일반적으로 어떤 자료구조를 사용하나요?
너비 우선 탐색(BFS, Breadth-First Search)은 일반적으로 큐(Queue) 자료 구조를 사용하여 구현됩니다. 큐는 먼저 들어온 요소가 먼저 나가는 선입선출(FIFO, First-In-First-Out)의 원리를 따르는 자료 구조이기 때문에 BFS에서 각 노드를 방문한 후 그 노드의 인접한 모든 노드를 큐에 순서대로 추가하여 순차적으로 탐색할 수 있습니다.
브루트 포스 방법은 무엇인지 간단하게 설명해 주세요.
브루트 포스(Brute Force) 방법은 문제를 해결하기 위해 가능한 모든 경우의 수를 일일이 확인하면서 최적의 해를 찾는 방법입니다. 브루트 포스 방법은 경우의 수가 많은 경우에는 비효율적일 수 있으며, 시간이 오래 걸릴 수 있습니다. 그러나 경우의 수가 제한적이거나 최적의 해를 찾는 다른 방법이 없는 경우에는 유용하게 사용될 수 있습니다. 또한, 브루트 포스 방법은 문제 해결 과정을 이해하고 구현하기 쉬운 편이라는 장점이 있습니다.
DB에 대해서 간단하게 정의해 주세요.
데이터베이스(Database)는 구조화된 데이터를 저장, 관리, 조작하는 데 사용되는 시스템입니다.
데이터 저장, 데이터 검색, 데이터 갱신, 보안, 동시성 제어, 백업 및 복원과 같은 기능을 가지고 있습니다.
데이터들은 테이블 형식으로 구조화하여 저장이 되며 각 테이블은 레코드와 필드로 이루어져 있습니다. 데이터 베이스의 장점으로는 여러 사용자가 동시에 사용이 가능하다는 점이 있으며 데이터의 공유와 협업이 유용합니다.
쿼리에 대해서 간단하게 정의해 주세요.
쿼리(Query)란 데이터베이스로부터 정보를 요청하거나 추출하기 위해 사용되는 명령어나 구문입니다. 즉, 데이터베이스에 저장된 데이터를 검색하거나 조작하기 위한 명령어를 의미합니다. 일반적으로 쿼리는 데이터베이스 관리 시스템(DBMS)의 쿼리 언어(SQL 등)를 사용하여 작성됩니다.
스키마에 대해서 간단하게 정의해 주세요.
스키마(Schema)란 데이터베이스에서 데이터 구조와 관련된 정보를 정의하는 데 사용되는 개념입니다. 스키마는 데이터베이스 내의 테이블, 열, 데이터 유형, 제약 조건 등에 대한 설계와 구조를 정의합니다.
간단하게 말하면, 스키마는 데이터베이스에서 어떻게 데이터를 구성하고 저장할지에 대한 청사진이라고 할 수 있습니다. 스키마는 데이터베이스의 구조를 설명하고, 데이터의 유형과 관계를 정의하여 데이터베이스 시스템이 데이터를 저장하고 처리하는 방법을 결정합니다.
Set 자료구조는 어떤 특성을 가지고, 어떤 상황에서 쓰이나요?
Set 자료구조는 중복된 원소를 허용하지 않고, 순서가 없는 요소들의 집합을 나타내는 자료구조입니다.
이러한 특성 때문에 다음과 같은 상황에서 주로 사용됩니다.
중복 제거: Set은 중복된 원소를 허용하지 않으므로, 중복된 항목들을 제거하고 유일한 값들만을 보관하는 용도로 사용됩니다.
집합 연산: Set은 집합 연산(합집합, 교집합, 차집합 등)을 지원하므로, 두 집합 사이의 연산을 쉽게 수행할 수 있습니다.
멤버십 테스트: Set은 특정 요소가 집합에 속해 있는지 여부를 효율적으로 검사할 수 있습니다. 이를 통해 어떤 원소가 집합에 포함되어 있는지를 빠르게 확인할 수 있습니다.
순서가 필요하지 않은 경우: Set은 요소들의 순서가 중요하지 않은 경우에 유용합니다. 예를 들어, 고유한 값들의 집합을 보관하거나, 순서가 중요하지 않은 데이터를 처리할 때 사용됩니다.
해시 테이블의 구현: Set은 해시 테이블을 구현하기 위한 기본적인 자료구조입니다. 이를 통해 효율적인 데이터 검색 및 삽입을 지원합니다.
join 연산에 대해서 설명해 주세요.
JOIN 연산은 관계형 데이터베이스에서 사용되는 데이터 검색 및 조작을 위한 중요한 연산입니다. JOIN 연산은 두 개 이상의 테이블에서 데이터를 결합하여 하나의 결과 집합을 생성합니다.
일반적으로 JOIN 연산은 두 테이블 간의 관계를 기반으로 수행됩니다. 공통된 키값이 있는 열을 선택하여 두 테이블을 연결합니다. JOIN 연산을 통해 연결된 두 테이블의 데이터를 결합하여 하나의 결과 집합을 생성하며, 이 결과 집합은 하나의 가상 테이블로 간주됩니다.
JOIN 연산은 여러 유형이 있으며, 주요한 유형은 다음과 같습니다:
INNER JOIN: 두 테이블 간에 일치하는 행들을 결합합니다. 즉, 공통된 값들을 가진 행들만 결과 집합에 포함됩니다.
LEFT JOIN (또는 LEFT OUTER JOIN): 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행들을 결합합니다. 만약 오른쪽 테이블에 일치하는 행이 없는 경우에도 왼쪽 테이블의 모든 행이 결과 집합에 포함됩니다.
SQLD문제를 풀어보자
- 업무에서 필요로 하는 인스턴스로 관리하고자 하는 의미상 더 이상 분리 되지 않는 최소의 데이터 단위는?
- 속성 (ATTRIBUTE)
- 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속된 상태를 무엇이라 하는가?
- 제2정규형
- CROSS JOIN(상호 조인)
한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시킨다.
상호 조인 결과의 전체 행 개수는 두 테이블의 각 행의 개수를 곱한 값이 되며 카테시안 곱(CARTESIAN PRODUCT)라고 함.
어렵다.,...... 문제집부터 사야겠다.
git 강의
브랜치
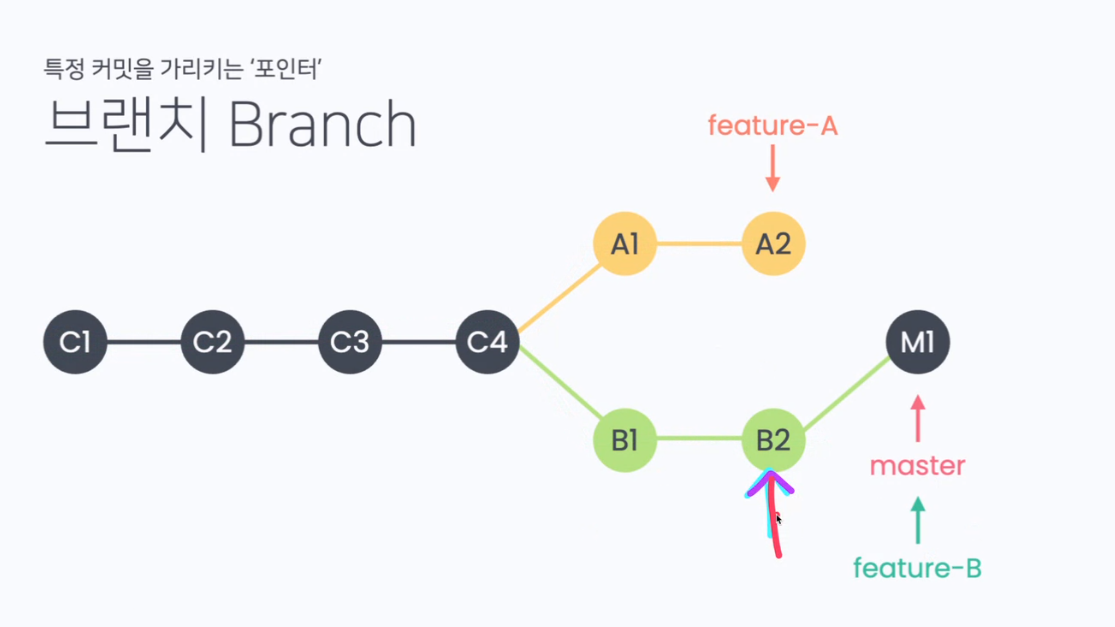
git switch -c {브랜치 이름}

오늘은 git에서 브랜치를 만들고 팀원과 공유하고 충돌을 해결하고 pr을 해보는 것을 해보았습니다.
생각보다 뜻대로 되지 않는다는 것을 보고 정신 승리를 하고 말았습니다...ㅎ.
'코딩 교육 TIL' 카테고리의 다른 글
| 2024-03-28 AI 코딩 TIL (0) | 2024.03.28 |
|---|---|
| 2024-03-27 AI 코딩 TIL (0) | 2024.03.27 |
| 2024-03-21 AI 코딩 TIL (0) | 2024.03.21 |
| 2024-03-20 AI 코딩 TIL (0) | 2024.03.20 |
| 2024-03-19 AI 코딩 TIL (0) | 2024.03.19 |