
팀 프로젝트를 시작해 봅시다!
GPT 웹종 팀 프로젝트를 만들어 보는 시간!
게시판 만들기~!
우리 팀에서 만들어 볼 것은 영화 게시판 입니다.
영화에 리뷰를 달고 그 리뷰를 서로 공유 하며 나누는 것을 목적으로 만들어 볼 것이고 구상은 아래와 같습니다.
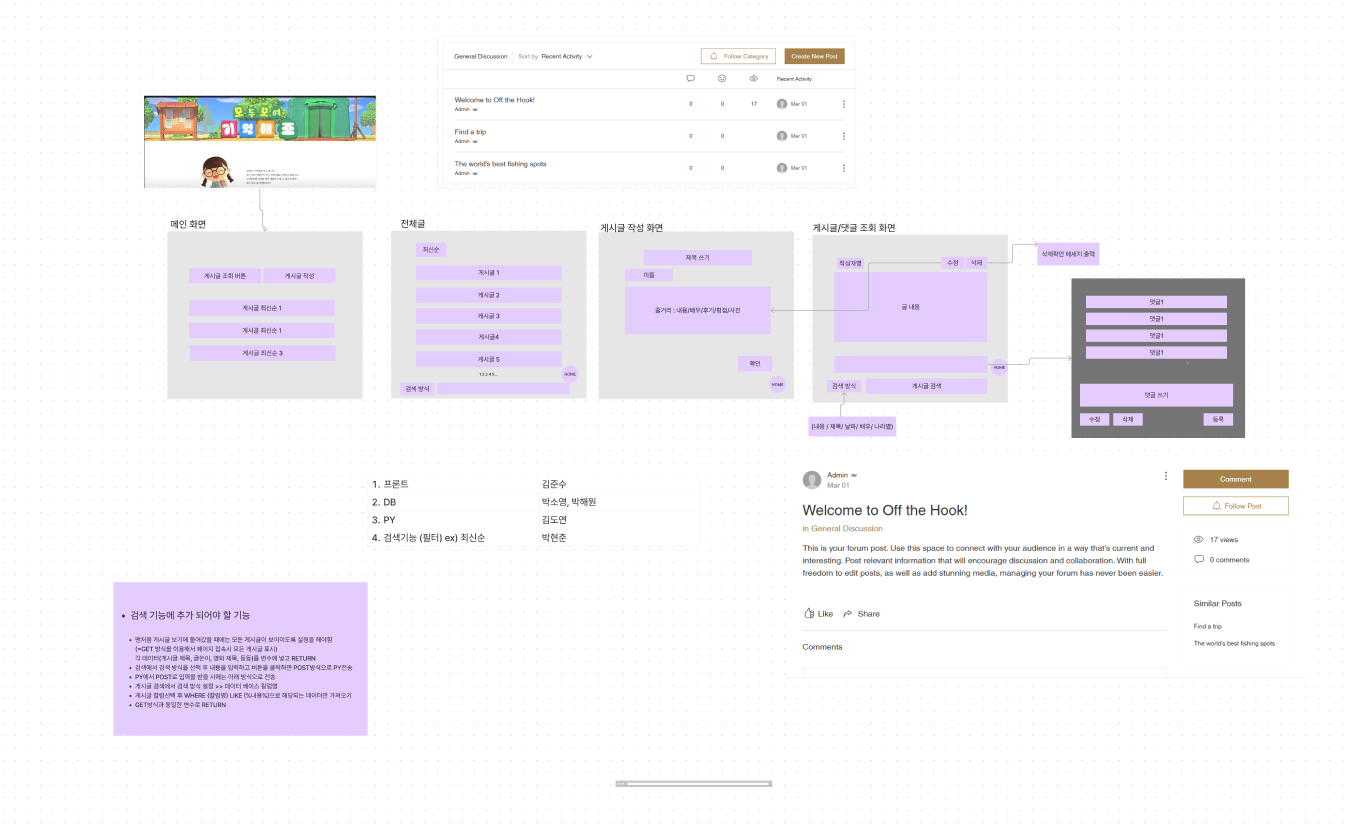
프론트 페이지를 만들고 각 기능을 나누어서 목적에 맞게 배분을 하는 형식으로 할 예정입니다.
이걸 만들면서 좋은 걸 알게 되었는 데 팀 프로젝트를 하면서 서로 공유하고 나누기 좋은 프로그램인 "피그마"라는 사이트로 들어가서 서로 같은 화면을 보면서 공유가가능 한 화이트 보드 같은 웹사이트입니다.
Figma: The Collaborative Interface Design Tool
Figma: The Collaborative Interface Design Tool
Figma is the leading collaborative design tool for building meaningful products. Seamlessly design, prototype, develop, and collect feedback in a single platform.
www.figma.com
또는 미로라는 사이트도 있다
무료 온라인 화이트보드 | 실시간 협업 | Miro
협업의 중심에서 온라인 화이트보드 그 이상의 경험을 제공합니다. Miro의 신속한 무료 디지털 화이트보드를 통해 언제 어디서나 원활한 협업을 경험하세요.
miro.com
- 사용하는 기술
- 프론트엔드 : HTML
- 프론트 엔드 : JavaScript
- 프론트 엔드 : CSS
- 백엔드 : Python(flask)
- DB : 미정
내가 맡은 파트는 게시글의 검색기능을 구현하는 파트입니다.
게시판 CRUD
- 영화 게시판 - 영화 후기 작성 및 추천
- 글 작성 - 팝업 OR 페이지
- 글 수정 - DB에서 내용을 가져와 글작성 페이지에 반영
- 글 삭제 - 삭제 확인 메세지를 알림 후 확인을 누르면 DB에서 삭제
- 게시판 글 조회 - (페이지 생성 이동) 글내용/ 제목/ 날짜/ 영화배우/ 나라
- 댓글 작성 - 게시글 아래 부분에 작성
- 댓글 수정 - 수정창을 만들어 내용 수정
- 댓글 삭제 - DB에서 삭제
- 댓글 조회 - 글내용/ 제목/ 날짜 (해당 페이지에서 조회)
먼저 기능을 만들기 위해서는 무슨 기능이 필요할까 생각을 해보았습니다.
- 검색 기능에 추가 되어야 할 기능
- 맨처음 게시글 보기에 들어갔을 때에는 모든 게시글이 보이이도록 설정을 해야함
(=GET 방식을 이용해서 페이지 접속시 모든 게시글 표시)
각 데이터(게시글 제목, 글쓴이, 영화 제목, 등등)를 변수에 넣고 RETURN - 검색에서 검색 방식을 선택 후 내용을 입력하고 버튼을 클릭하면 POST방식으로 PY전송
- PY에서 POST로 입력을 받을 시에는 아래 방식으로 전송
- 게시글 검색에서 검색 방식 설정 >> 데이터 베이스 칼럼명
- 게시글 칼럼선택 후 WHERE {칼럼명} LIKE {%내용%}으로 해당되는 데이터만 가져오기
- GET방식과 동일한 변수로 RETURN
- 맨처음 게시글 보기에 들어갔을 때에는 모든 게시글이 보이이도록 설정을 해야함
- 검색 기능을 만들기 위해서 생각해야 할 절차
- 유저의 DB의 테이블과 게시글 DB의 테이블을 따로 만들어 주어 게시글의 글쓴이와 유저의 ID를 매칭하여 주는 구조를 생각해 보아야함
- DB에 들어가야할 스키마를 구성해보자.

- 내가 준비해야 할 부분

태그에 맞추어 내용을 입력하고 거기에 맞는 게시글의 내용만 가져오도록 하자.
@app.route("/전체글조회", methods=["POST", "GET"])
def 전체글조회():
cur = get_cur() # DB와 연결
per_page = 10 # 게시글 10개 씩
page, _, offset = get_page_args(per_page=per_page)
# POST request라면,
if request.method == "POST":
query = request.form["find"] # 전체글 조회에서 입력칸에서 받은 "find"글자
tag = request.form["tag"] # 전체글 조회에서 검색방법으로 선택한 "tag"글자
query_for_like = ("%" + query + "%").lower() # 검색 편의를 위해 소문자로 변환
# 게시글 수 파악
cur.execute(
"SELECT COUNT(*) FROM 테이블명 "
"WHERE %s LIKE %s;",
(tag, query_for_like), # 포스트 제목과 내용도 소문자 변환해서 검색
)
total = cur.fetchone()[0] # 데이터베이스에서 가져온 결과 집합의 첫 번째 행에서 첫 번째 열의 값
# 게시글 내용
cur.execute(
"SELECT p.아이디, 내용, 제목, 날짜, 영화이름, 리뷰, 평점, 이름 "
"FROM 게시글DB p JOIN 유저DB u ON p.아이디 = u.아이디 "
"WHERE %s LIKE %s "
"ORDER BY created DESC;", # POST라면 LIKE 검색 결과를 보여줌
(tag, query_for_like),
)
# POST가 아니라면, 즉 GET request라면,
else:
cur.execute("SELECT COUNT(*) FROM 게시글DB p;") # 게시글 수 파악
total = cur.fetchone()[0]
cur.execute( # GET이라면 검색 없이 모든 포스트를 보여줌
"SELECT p.아이디, 내용, 제목, 날짜, 영화이름, 리뷰, 평점, 이름 "
"FROM 게시글DB p JOIN 유저DB u ON p.아이디 = u.아이디 "
"ORDER BY 날짜 DESC;", # 생산 일자 역순으로
(per_page, offset),
)
# 모든 데이터 베이스 값 딕셔너리화 하기
posts = cur.fetchall()
return render_template("전체글 조회.html",
posts=posts, # 게시글 내용
pagination=Pagination(
page=page, # 지금 우리가 보여줄 페이지는 1 또는 2, 3, 4, ... 페이지인데,
total=total, # 총 몇 개의 포스트인지를 미리 알려주고,
per_page=per_page, # 한 페이지당 몇 개의 포스트를 보여줄지 알려주고,
)아직 데이터 베이스가 없어서 실행을 해보지는 못했다.
데이터 베이스가 완성이 되는 데로 동작 확인을 해보자.
아래의 블로그들에서 정보에서 기반하여 생각했습니다.
Flask 블로그 제작기 (6) - 검색 기능 (tistory.com)
Flask 블로그 제작기 (6) - 검색 기능
플라스크로 서비스되던 구버전 블로그에서 옮겨왔습니다. 검색(search)과 정렬(sort)은 알고리즘계의 양대산맥입니다. 자료구조에 따라 다양한 방식으로 검색과 정렬을 구현할 수 있지만, 그 때 그
panda5176.tistory.com
3-14 검색 - 점프 투 플라스크 (wikidocs.net)
3-14 검색
* `[완성 소스]` : [github.com/pahkey/jump2flask/tree/3-14](https://github.com/pahkey/jump2flask/tree/3-…
wikidocs.net
'프로젝트 과제' 카테고리의 다른 글
| 영화 리뷰 게시판 만들기 - 팀 프로젝트 3일차 (0) | 2024.04.03 |
|---|---|
| 영화 리뷰 게시판 만들기 - 팀 프로젝트 2일차 (0) | 2024.04.02 |
| (개인 과제) 가위 바위 보 게임 웹으로 만들기! (0) | 2024.02.26 |
| (개인 과제) 클래스 사용해보기! (1) | 2024.02.23 |
| (개인 과제) 가위 바위 보 게임 만들기! (0) | 2024.02.22 |